
2. [21년 10월 ~ 21년 02월] 새로운 도메인을 위한 데이터 마이그레이션과 그 이후
1차 데이터 마이그레이션
- 세 개의 새로운 도메인에 대하여 새로운 데이터가 출현했고, 과거 데이터를 spring batch를 통해 함께 이관시킴.
- 약 4천 건의 프로덕트 맵핑 데이터 생성
- 약 9만 건의 유저에 대한 월렛 데이터 생성
- 약 1만개에 대한 멤버십 데이터 생성
- 이에 따라, 유저가 소유한 서비스 권한 및 멤버십이 기술화됨
2차 데이터 정합성 맞춤 알림
- 서로 다른 도메인이지만 한 싸이클 내에서 정합해야하는 데이터들이 있음.
- 유저의 서비스 권한 - 이용할 수 있는 티켓 - 환불 이력
- 정합성 불일치 시, 메일 / 슬랙 알림이 오도록 자동화. 10분에 한번씩 Event Bridge - Lambda 트리거를 이용하여 정합성 체크 실행
3차 데이터 보정(분석)
- 정합성 오류시 원인을 찾아 데이터 보정을 진행.
- 해당 과정에서 도메인에 있는 빈틈과 버그를 찾아냄.
- 상품 변경 시, 기존 멤버십에 대한 상태 변이가 되지않는다.
- 같은 상품 환불 후 재구매 시, 처음 구매한 멤버십에 대한 상태 변이가 되지 않는다.
- 환불 시점에 따라 종료될 수 있는 멤버십이 달라져서 재구매 시, 멤버십 생성이 실패한다.
- 결제 수단 변경 시, 멤버십 권한이 사라진다. 등
4차 데이터 비정합 시, 슬랙 노티 개선 - "빠르게 확인하고 빠르게 보정한다"
- 실패 원인을 빠르고, 정확하게 인지하는 것이 목표였음.
그 외,
📍 데드큐에 있는 메세지를 어떻게 가져왔을까?
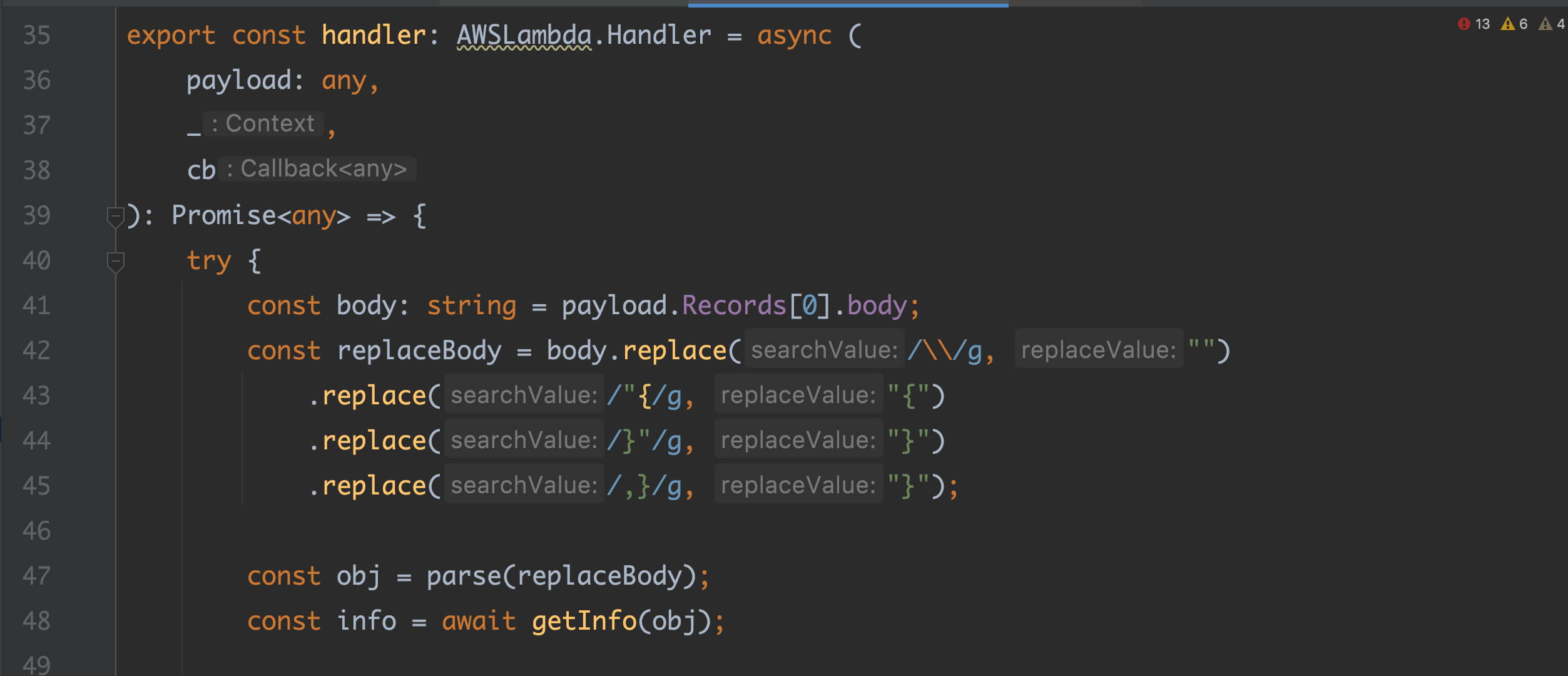
DLQ 에 쌓이면 람다가 캐치 👉🏽 메세지 파싱 👉🏽 슬랙 api 를 통한 알림 메세지 전송
📍 분산 트랜잭션 처리를 위한 방안에 대해서
데이터 정합성을 맞추기 위해서는 다음과 같은 방안이 있다.
- 대기 또는 실패 시에 다시 호출
- 실패 시 일괄 취소
- 보상 트랜잭션 처리 (Saga 패턴과 관련됨)
이 세 가지 중, 한 가지도 우리 시스템 내에서 보장해주지 못하고 있었기에, 데이터 보정작업이 계속 필요했다. (현재는 보상 이벤트 발행 시도를 앞두고 있다)
📍내가 데이터 보정 자동화 처리를 시도했다면
알람이 올 때 마다 데이터 보정을 자동으로 처리해주는 애플리케이션을 개발했다면 불필요한 리소스를 덜 수 있었을 것 같다. 한참 자주 발생할 때는 하루에 10건도 넘었다. 1건에 대해 데이터 보정을 처리하려면 평균 5분은 걸렸다. 당연히 컨텍스트 스위칭이 일어난다. 근데… 예외가 일어난 데이터에 대한 보정을 자동화하는게 맞을까? 우리 도메인은 왜 예외가 일어난 데이터에 대해서 알림을 받고 있었을까. 왜 보정을 직접 해주어야했을까.
데이터 비정합은 주로 먼저 발생한 이벤트에 의해 상태 전이가 실패하여 이후로 오는 이벤트가 연쇄적으로 실패하는 것이 주 원인이었다. 자주 발생하던 그 시기는 해당 도메인이 완벽하게 성숙된 상태가 아니었다. 이제 막 릴리즈된 따끈 따끈한 도메인이었다. 직접 데이터 보정 작업을 하면서 자주 살펴보다보니 몇 개의 비즈니스 구멍을 발견하기도 했다. 나 뿐만 아니라 테크 유닛 모두가 그 알림을 받았다. 다른 작업 중에도 알림을 받고, 수고스러움을 감수하면서 데이터를 살펴보고, 관련 로직에 대한 빈틈을 인지하는 시간이 모두에게 필요했다는 생각이 든다. 덕분에 자연스럽게 도메인에 대한 지식이 평준화되었다. 관련 도메인에는 현재 무슨 이슈가 있는지, 어떤 개선 작업을 해야하는지. 모두가 알고 있었다. 이 후, 우리는 해당 도메인에 빈틈을 조금씩 메꿔갔다. 현재는 더 이상 데이터 비정합 알람을 받지 않는다.
3. [22년 01월 ~ 22년 03월] 새로운 형태의 상품 등장 그리고 레거시 1편
트레바리에서 파는 상품 중 하나인 독서모임 멤버십은 기본 4개월이다. 레거시 코드에서 4개월 기준으로 하드 코딩되어있는 로직이 많은 이유다. 새로운 형태의 독서모임 멤버십을 끼워넣을 공간이 없었다. 우리는 기존 코드가 새로운 상품 등장에 대한 변화를 수용하지 못한다는 것을 인지하기 시작했다. 바로 닥친 릴리즈는 일주일의 시간 밖에 할당받지 못했다. 그래서… 하드코딩 + 코드 복붙 + if 문 추가의 쓰리 콤보로 릴리즈 했다. 문제는 해당 코드들의 잔재가 아직도 남아있다는 거다. (해당 상품은 현재 더 이상 구매할 수가 없는데도 !). 누군가는 하겠지 같은 마음인가? 나는 “레거시는 원래 그러니까” 같은 흑화된 마음이었다. 조금씩 잔재 코드를 없애왔다면 이 작업이 그래도 덜 수고스러웠을 것 같다. 5년 전부터 덕지덕지 붙여진 하드코딩들을 조금씩 없애 와야했다. 모두 관심과 정성이 부족했다. 우리가 클렌징 프로젝트를 시작한 이유다.
CTO님이 자주 하는 얘기 중에, 이만하면 다 되었다 하는 마음에서 조금 더 해보자의 그 조금은 항상 어렵다고 하셨다. 요즘 그 말씀이 자주 떠오른다. 현재까지의 경험상, 유효하지 않은 코드는 지금 제거안하면 영원히 안한다. 한번 todo 는 영원한 todo 다. 주석도 불필요한 것 같다. 코드 설명은 코드로만 하는게 나도 좋고 너도 좋은 것 같다. 그래서 테스트 코드가 있어야 하지 않을까. 복잡한 정산 도메인에 테스트 코드 가 있다면 그걸로 설명이 되니까. 나… 경험이 조금씩 쌓여가고 있는 것 같다.
+ 최근 CTO 님의 주도로 레거시 부분 개선이 시작되었다. 테스트가 도입되었고 분리와 느슨한 결합을 위한 기반작업 중이다. 체크아웃 페이지를 도출해내고 있다. 특정 상품이 아니라 어떤 상품이든 한 로직을 통해서 신청 및 결제되는 형태를 우리는 꿈꾸고 있다. 나는 여기서도 굉장히 많은 것을 배웠는데, 그 부분은 추후에 업로드 할 예정이다.
4. [ 22년 02월 ~ ] 시스템 안정화를 위한 쉽고 빠른 액션 아이템은?
올해 2월 부터 버그가 자주 발생하기 시작했다. 시스템 안정화를 위한 액션 아이템을 몇 가지 발굴했다.
“log를 명확히 하자”
우리가 겪은 이슈 중에 어떤 것들은 어떤 요청에 의해 어떤 에러가 나가고 어떤 응답이 나갔는지 전혀 알 수가 없었다. log 개선을 시작한 이유다. 우선 응답코드 500이상에 대한 로그를 정리해보기로 했다. 사용하지않고 보지않는 로그는 일괄 삭제처리했고, 약 228개의 로그에 대해 개선했다. 예외가 아니면 제거하고 오류라면 더 명확하고 자세하게 로그를 심는 식이었다. 해당과정에서 에러와 오류를 구분하고 로그에 대한 role 을 기술정책화했다. 예를들면 payment 에서 결제 전 valid 검증에서의 오류라면 이런 식이었다.
payment::application::alreadyMaxMemberValid::{userId}::{clubId}+ ) 위 예시에서도 보면 알 수 있겠지만, 특정 상품에 대한 경직되어있는 것을 볼 수 있다. {clubId} 더 나은 방향이라면 productOptionId 가 될 것 같다.
“유저가 적어도 로그인은 가능하게 하자”
서버가 뻗으면 유저는 모든 서비스를 이용할 수 없었다. 유저 경험을 그나마 덜 해치기 위한 시도로 백엔드 레포에 있던 로그인 모듈을 분리하여 로그인 서버 따로 두었다. (해당 과정에서 많은 레거시 코드도 함께 제거했다.) 한 서버에 문제가 있을 경우, 다른 서버까지 연달아 터지는 사이드 이펙트를 줄일 수 있게되었다. 유저는 적어도 로그인은 할 수 있게되었다. 근데 그때는 "다른 기능이 정상적이지 않은데 로그인만 되어서 뭘하나..?" 같은 생각이 들었다. 지금 생각해보면, 하나하나의 기능을 독립적으로 떼어서 분리하려는 최초의 시도였던 것 같다. 상품과 결제가 잘 분리되야하듯이 서로 얽혀있는 것들을 격리시킨다. 이게 포인트였다. 근데 이렇게 분산시키는 것과 하나로 서비스를 관리하는 monolithic 식의 방법 중에 어떤게 우리 서비스에, 우리 리소스에 더 나을지는 고민을 좀 더 해봐야할 것 같다.
"장애 대응 메뉴얼을 만들자" 📝

1. 이슈가 발생하면 장애 대응 슬랙 채널을 개설하고 테크유닛 구성원을 초대한다.
2. 타임라인을 공유하고 전사 공유한다.
* 최초 발견 시간, 장애 안내 페이지 전환 시점, 롤백 전환 시점 공지
3. 고객에게 장애 안내 페이지로 트래픽을 전환시키고, 내부 장애 확인 주소로 인스턴스를 전환시킨다.
4. 최근 배포 사항을 확인하고, 태그 롤백한다.

5. 원익 파악 및 장애 대응을 진행한다.
6. 이슈 종료 시 보고서를 작성한다.
* 보고서에는 액션 아이템이 포함된다.
5. [ ~ 22년 04월 ] SMS 개선 : 스케쥴링을 관리해드립니다.
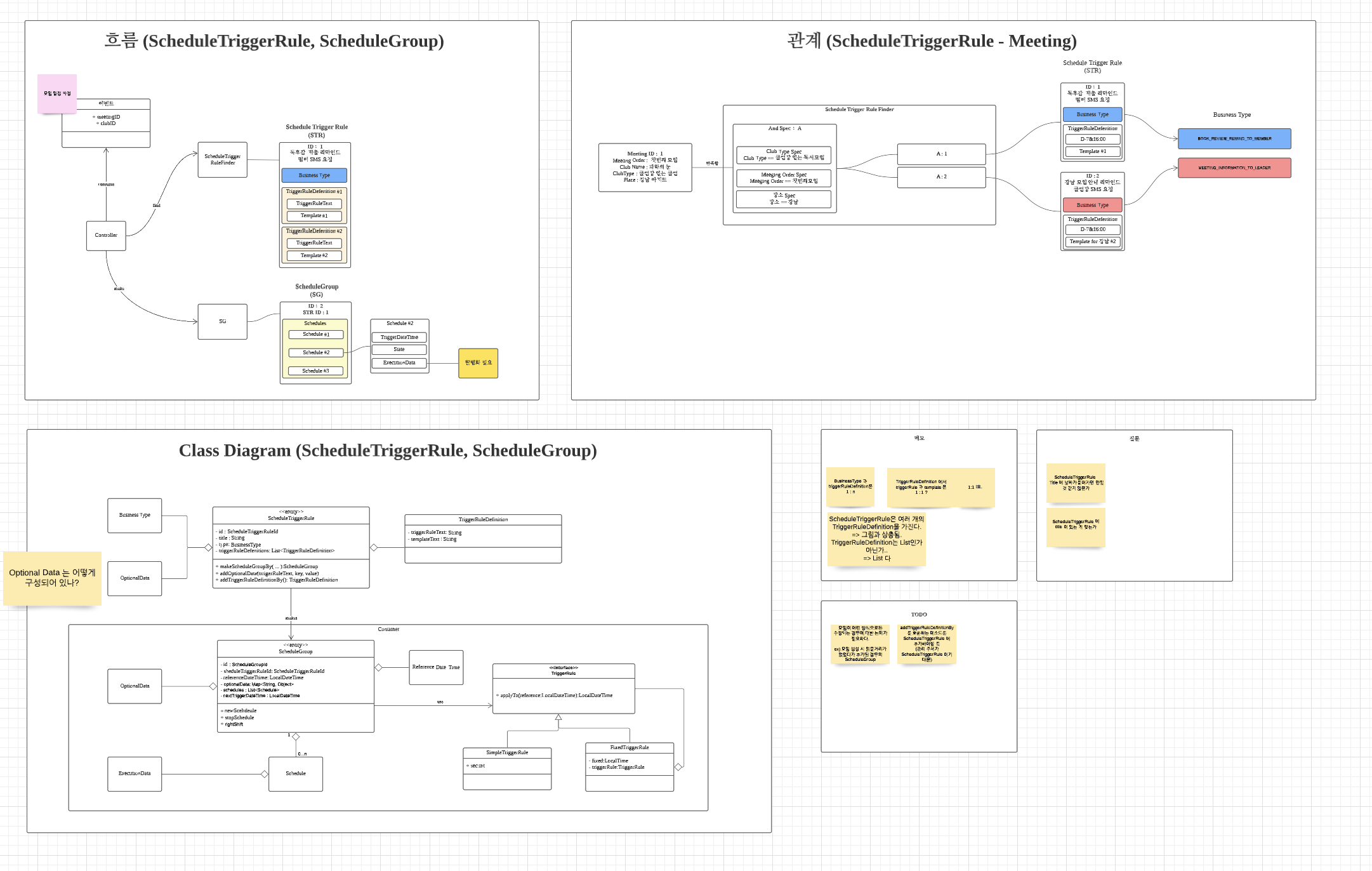
자사 서비스가 유저에게 (불)규칙적으로 전송하는 문자들이 있다. 모임 안내 문자 또는 피드백 문자 등등 약 145 개의 문자 템플릿이 있고 정해진 시간마다 유저에게 해당 문자가 전송된다. 운영하는 크루들은 문자가 제대로 전송이 되었는지, 전송 대상이 잘못되진 않았는지 매일 체크했다. 크루들의 업무 효율을 덜고자 SMS 개선 프로젝트가 시작되었다. 여기에 두 가지 가치가 있다.
- 문자 보내는 사이트(샌더스, 토스트) 에 접속하지 않고도 크루는 어드민을 통해 전송 여부를 빠르게 확인한다
- 어드민에서도 문자 전송을 할 수 있다.
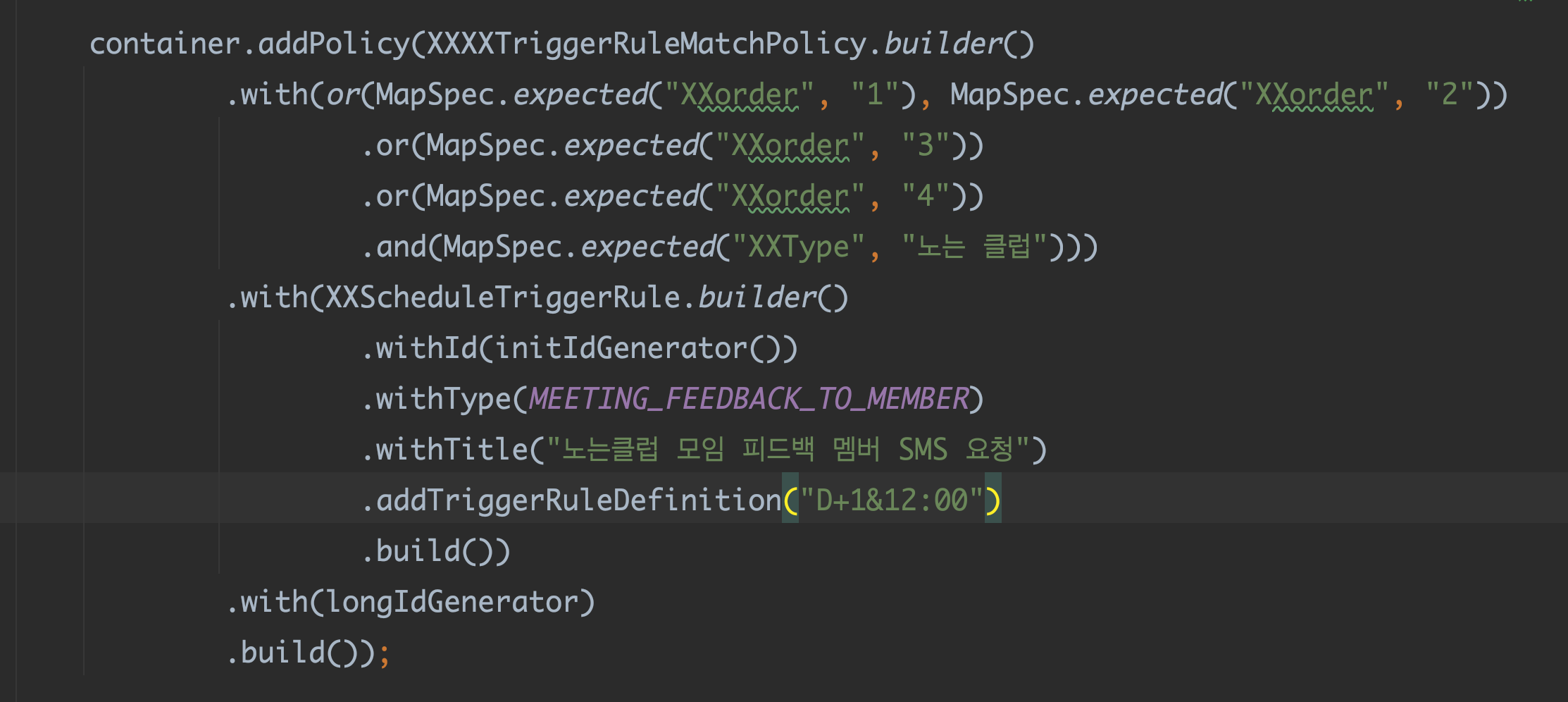
Specification Pattern 을 이용했다. 미리 정의한 룰이 조건에 맞다면 문자 예약 전송 리스트에 추가시키는 방식으로 구현했다. 총 145 개의 문자 템플릿, 총 20 개의 스케쥴링을 커버한다. 새로운 문자 템플릿이나 스케쥴이 추가되면 해당 컨테이너에 정책만 추가하면 끝이다. 여기까지 개발을 하다보니 해당프로젝트는 스케쥴링 성격이 강하다는 것을 알게 되었다. SMS 뿐만 아니라 스케쥴링이 필요한 모든 것에 대해 트리거가 되는 거다. 여기에 어떤 서비스를 더할 수 있을까. 독후감 마감 스케쥴에 따라 문자도 보내고 슬랙으로 모여진 독후감을 전송하는건 어떨까. 운영 크루가 확인하고 빨리 독후감을 확인할 수 있도록!
+ 위 사진에서 보다시피 스케쥴이 추가되면 코드의 수정을 해야한다는 점이 좀 걸린다. 어떻게 개선할 수 있을까. 해당 컨테이너를 따로 파일로 관리해서 가져다 사용하게끔 하는 건 어떨까.
📍Specification Pattern ?
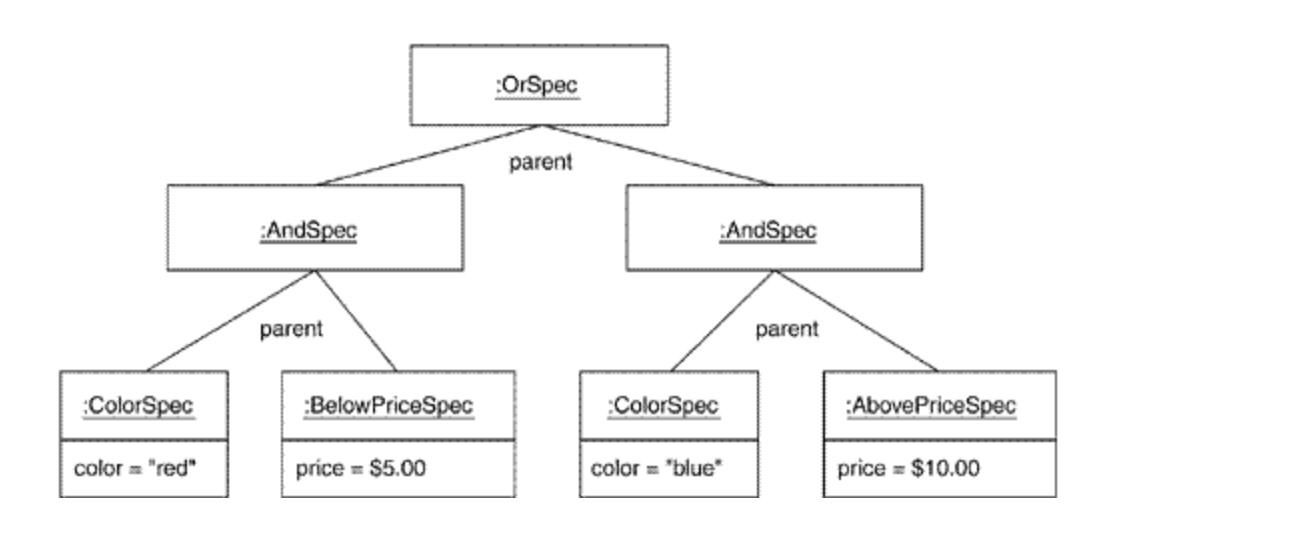
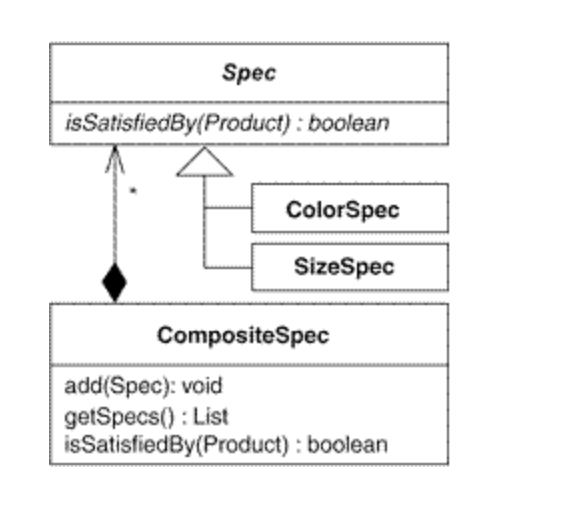
다음과 같은 이점이 있었다.
- 코드 중복 제거
- 클라이언트 코드가 간결해짐.
- 클라이언트에서는 조건에 따른 결과 합산과 같은 성가신 작업을 할 필요 없음.
조금 더 찾아보니 CompositePattern 으로도 불리는 것 같다.
+ fault tolerance
toast 쪽 서버 문제로 스케줄링 되어 있던 문자 전송이 일괄 실패 된적이 있었다.
toastApi 를 이용한 문자 전송이 실패하면 senders로 바로 요청이 되게끔 개선하는 작업도 여기서 포함되었다.
6. [ ~ 22년 05월 ] Event Store 첫 데뷔 : 개발 패러다임의 변화
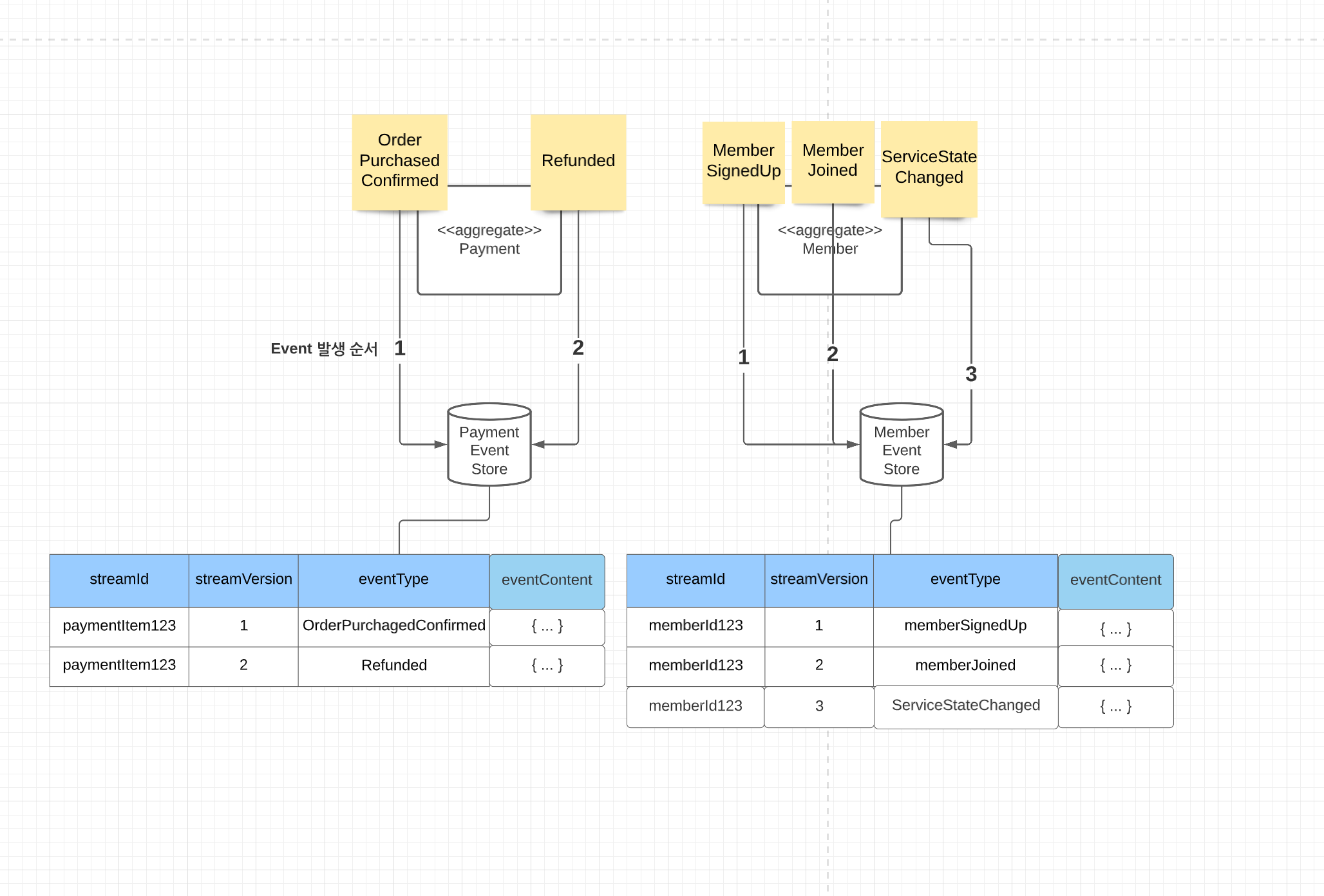
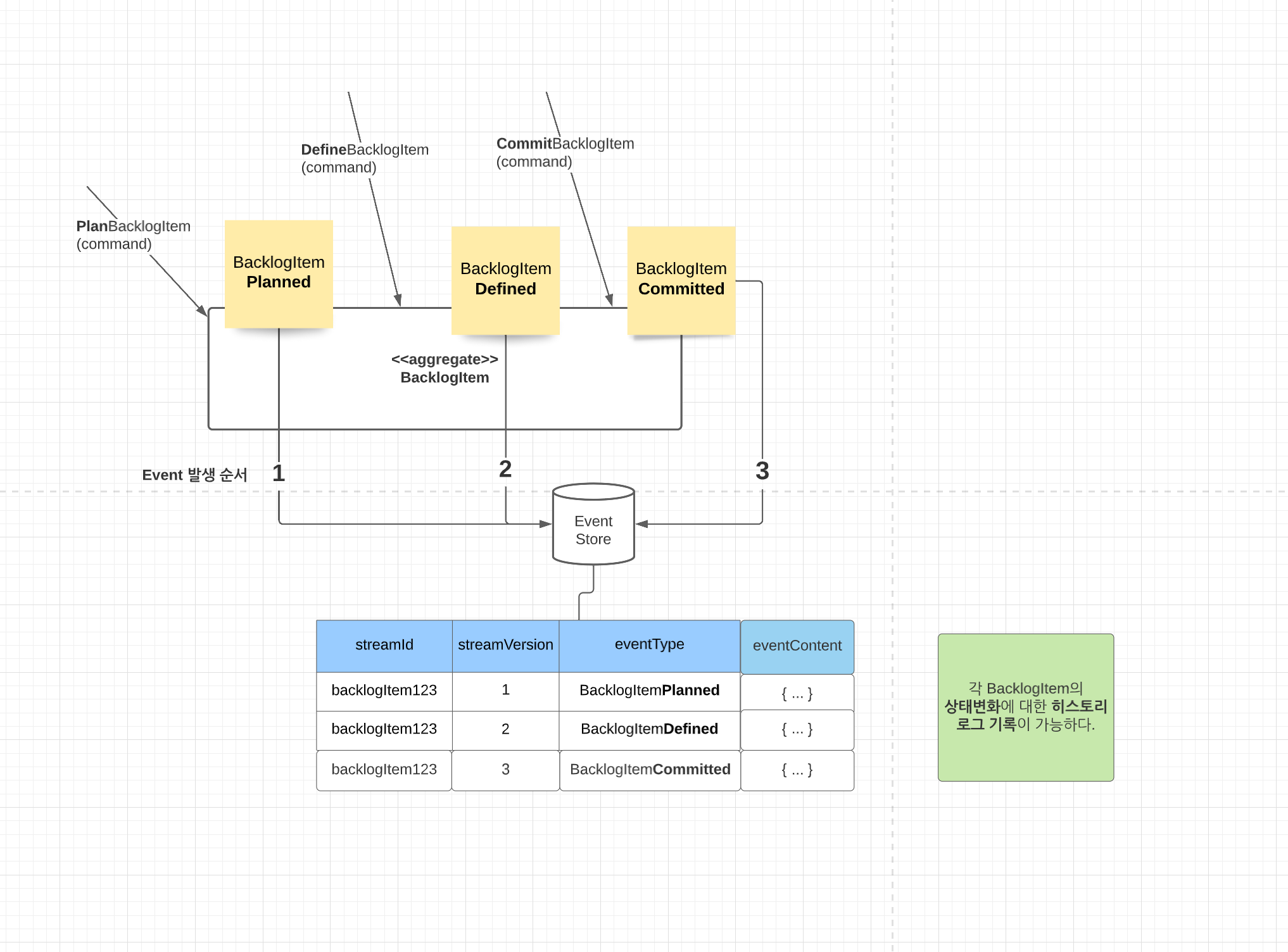
22년 5월을 기점으로 트레바리 서비스는 이벤트 스토어 기반으로 개발하기 시작했다. 이전과 비교해서 개발의 패러다임이 완전 달라졌다. 이벤트 스토어의 장점은 무엇이 있을까.
- 이벤트(사건)을 중심으로 다른 팀과 커뮤니케이션 할 수 있다
- 모든 데이터를 한 곳에서 파악할 수 있다. = 숨겨지지 않고 모두 드러난다!
- 이벤트 소싱을 replay 할 수 있다. (이 특징이,, 결제 환불 원장에서 많은 도움이 되었었다!)
근데 그만큼 단점도 존재했다.
- 버전 별로 도메인에 적용시켜주는 애플리케이션 단의 코드 양이 상당히 많았다. 😅
- 중복되는 코드가 상당히 많았다는 말이다. 😅
- 진입장벽이 있는 편이다. 첫 시도가 어렵다.
- 그래서 우리는 이벤트 소싱은 아니고 그 방식을 모방하여 비슷한 구조를 만드는 것으로 시도했다.
경험을 하고 난 뒤, 도메인 이벤트를 이벤트 레파지토리에 유지하는 것은 도메인 모델 간에 발생한 것에 대한 인과관계의 순서를 지켜준다는 것도 큰 의미가 있는 것 같았다. 핵심 도메인에서 발생하는 모든 기록을 개별적으로 그리고 순차적으로 저장한다는 점이 행여 모를 상황에 대비해 저장해두는 씨앗저장소같은 느낌이 났다. 든든한 느낌??
+ 이건 찾아보다가 알게 된 건데, 소스 코드를 디버깅하고 이벤트 사용 추세를 조사할 때 이벤트 스트림을 사용할 수 있다고 한다. 나중에 이것도 해보고 싶다.
내 역할은 필요한 이벤트를 리스트 업 하고 각 이벤트의 성격을 고려하여 그리고 확장성을 고려하여 이벤트 payload 정의 하는 거였다. 구현을 고려하지 않고 payload의 depth 를 너무 많이 주면 애플리케이션 단에서 스트림 사용이 빈번하게된다. 그래서 과도하게 중간 forEach 문을 사용하기도 했다. 그리고 payload 를 보고 각각의 필드 의미를 누구나 다 알 수 있는 용어와 우리 만의 특수성이 단긴 도메인 용어 중에 고민을 하기도 했다. 예를 들면 payment method 는 지불 수단을 의미하는데 우리는 payment method 라는 용어보다 paidLines 라는 도메인 용어를 사용했다. 이유는 같은 depth 에 걸쳐져 있는 필드 네이밍을 맞추기 위함이었다.
예를 들면 이런식 !
orderLines {
orderLine
},
paidLines {
paidLine
}
처음 이벤트 스토어에 저장되는 이벤트 타입은 5개였다. 그리고 지금은 25개다. 쌓여있는 이벤트를 세보자면 12,145,449 개다. 점점 불어나고 점점 많아지고 있다. 이 많은 이벤트 중에는 처음부터 정의가 잘못된 payload 를 가지고 있는 이벤트도 있고 정의는 잘 되어있지만, 잘못된 데이터가 들어간 payload도 있다. 이런 경우는 이벤트 자체가 잘못되어있어서 소비를 해도 문제가 있다. 해당 이벤트가 순서와 인과관계에 영향을 받는 도메인에 속한다면 좀 더 진지한 문제가 된다. 이후에 연쇄적으로 발생되는 이벤트에 영향을 지속적으로 주거나 해당 이벤트 실패로 인해 다음 이벤트 소비를 못하는 경우가 발생할 수도 있기 때문이다. 한번 발생한 이벤트 payload를 수정하는 것이 맞을까? 대개의 경우에 발생한 이벤트에 대한 수정은 없어야 하는 게 옳다고 한다. 그치.. 그게 맞는 방향이라는 생각이 든다. 그래서 이런 경우 보상 이벤트 발행이라는 개념으로 잘못된 페이로드를 바로 잡는 추가 이벤트를 발행시켜야 한다. 근데... 아직 사용하는 도메인이 없을 때라서 payload를 수정하는 것이 빠르다면..? (실제로 결제 환불에서는 depth 가 다른 payload를 선별해 버전을 수정했다. 바람직한 방향은 아니었지만, 가장 빠른 방법이었다.) 이 외에도 트랜잭션 아웃박스가 보장되지 않은 상황에서의 이벤트들도 있다. 변경해야한다. 또한 수동으로 한 프로세스를 처리해줄 경우(sqs message를 수동으로 처리할 경우) 관련한 또 다른 이벤트스토어의 이벤트들은 현재 이가 빠져있다. 이제 보상이벤트에 대해 다 같이 얘기해볼 때가 되지 않나싶다.
+ 같은 이벤트 타입에 대해 version 과 payload가 다른데, 이것을 관리할 수 있는 방법도 고려를 해봐야할 것 같다. 자사 서비스에 있는 이벤트 중 버전이 5개가 넘는 이벤트 타입이 있는데 payload 차이를 확인하려면 직접 일일히 비교하는 수 밖에 없다. 관련된 문서가 있지만 문서는 문서일 뿐........
7. [ ~ 22년 06월 ] Materialized View with 뉴 어드민 : "개발자니까 ( ? )는 책임져야지"
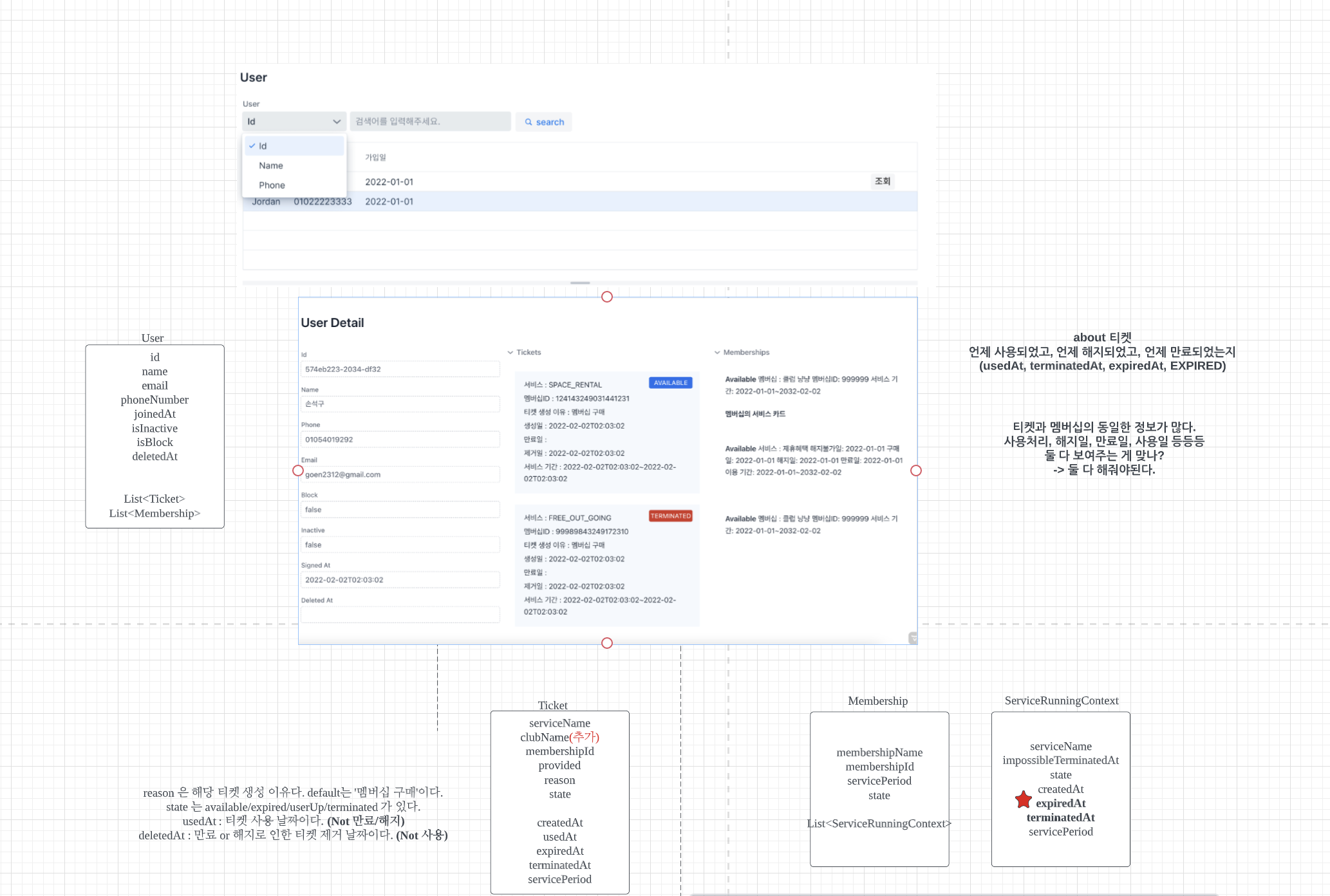
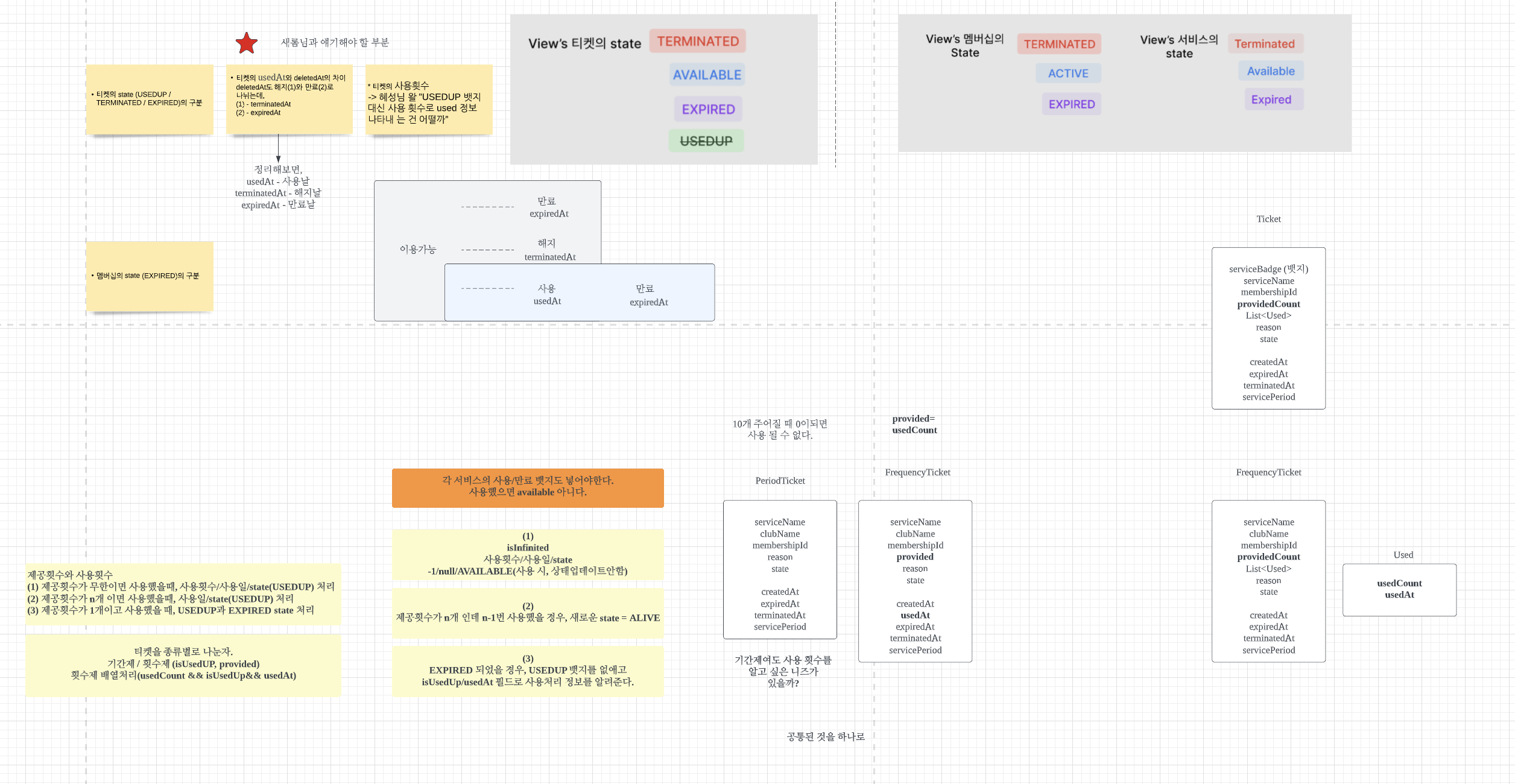
vaadin 으로 개발했던 이유
- 비즈니스 로직(도메인)과 UI코드 분리가 수월한 프레임워크다.
- 주어진 시간은 짧았고, 프론트엔드(css)에 대한 숙련도가 낮았다.
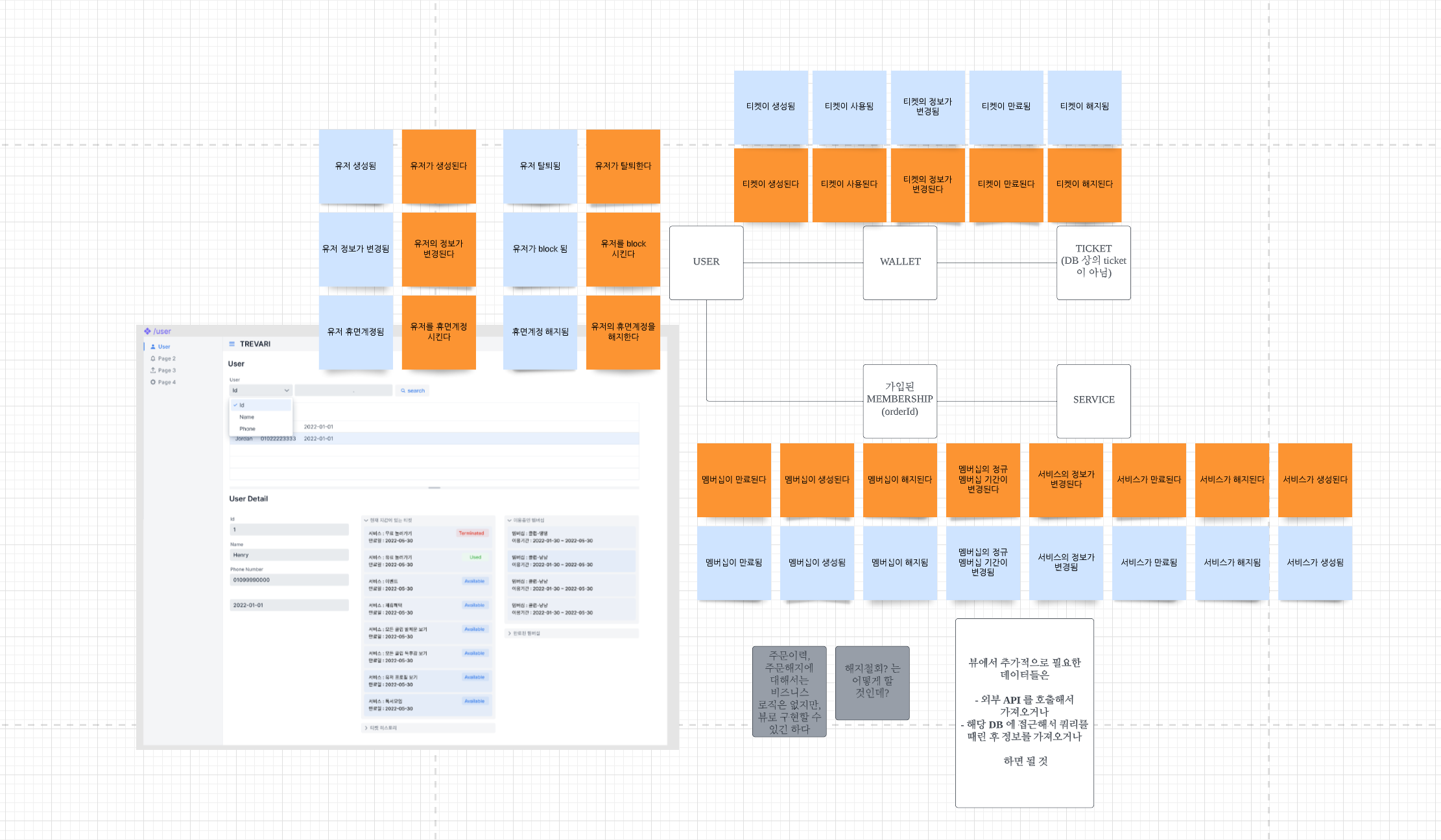
UI에서 모델링을 뽑아내는 것으로 개발을 시작했다. 해당 뷰에서 보고 싶은 것은 3가지였다.
- 유저의 정보
- 유저가 소유한 서비스 권한
- 유저가 구매한 멤버십 이력
이 뷰와 관련하여 필요한 이벤트는 총 19개였다. EventStore 작업을 하시는 분들한테 해당 이벤트를 relay 할 수 있도록 요청했고 그들은 그들대로, 나는 나대로 view 작업을 할 수 있었다. 이렇게 UI에서 필요한 정보를 먼저 뽑아내면 필요한 것만 개발할 수 있게 된다. 그 반대의 플로우로 갔을 경우, 불필요한 개발이 생길 수 있고 플로우가 길어질 수 있었다. fakeData 를 만든 이유도 이 때문이다. static 하게 만들어놓고 백에 의존하지 않고 뷰 단부터 우선적 개발이 가능했다.
css 에 대한 숙련도가 낮아도 프론트 단 개발은 어렵지 않았다. vaadin은 자바 기반으로 만들어져있어서 vaadin design 을 이용하면 드래그로 쉽게 Ui 컴포넌트를 추가하고 데이터를 매핑시킬 수 있다. 아주 예전에 사용했던 타임리프와 벨로시티와 비교하자면 어느정도 러닝커브가 있긴 하지만, 훨씬 빠르고 수월하게 애플리케이션을 제작할 수 있을 것 같다. 소스코드로 UI 를 컨트롤 한 경험은 처음이었다. 주로 제공된 레이아웃 템플릿에 버튼이나 테이블같은 콤포넌트를 붙이는 식으로 구성했다. 비즈니스 로직과 애플리케이션 로직 그리고 표현하는 UI 로직을 쉽게 분리할 수 있다는 점이 큰 장점이다. 자바 기반이라 내가 적응하기에도 어렵지 않았다. 단점이 있다면 너무 무겁고 느렸다. 😂
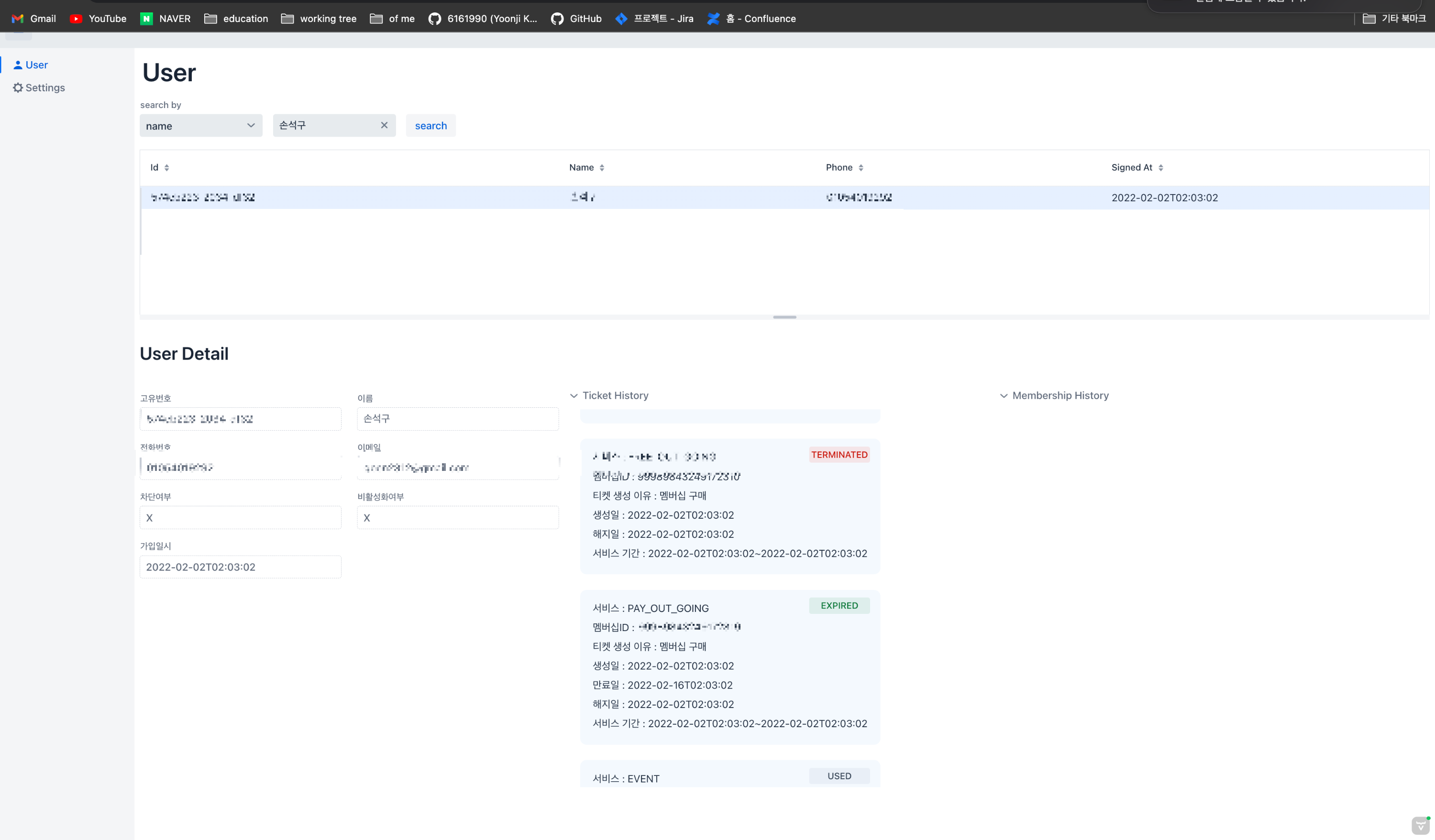
해당 작업으로 얻을 수 있는 최종적 가치는 다음과 같았다.
- 뉴 어드민에서는 유저의 정보를 필터별로 검색할 수 있다.
- 출현되고 있지 않았던 유저의 티켓과 멤버십을 크루가 확인할 수 있다.
이건 소프트 웨어의 행위적 가치다. 사용자(트레바리 크루)가 가진 문제를 해결해주는 가치다. 개인적으로는 소프트웨어의 중점적 가치라고 생각하고 있다. 비즈니스의 문제점을 해결해주고 때로는 더 크고 중요한 비즈니스 가치를 드러내 줄 수 있기 때문이다.
이 행위적 가치 말고도 소프트 웨어에는 다른 중요한 가치가 하나 더 있는데, 비즈니스 작업(프로젝트)을 기획과 개발로 무식하게 나눴을 때 주로 개발자만이 고민하고 책임지고 있는 가치다. 명명하자면 구조적 가치다. 구조적 가치는 변경하기 쉬운 소프트 웨어를 만드는 것이다. 뉴 어드민을 개발할 때, 한쪽에서는 트레바리에서 일어나는 사건(이벤트)들을 한데 모으고 있었다. 유저의 가입, 유저의 정보변경, 유저의 탈퇴 모두 이벤트다. 뉴 어드민에서 보여주는 유저의 모든 정보도 그 작업 덕분에 가능했지만, 이벤트 스토어 작업은 어드민에서만 사용할 목적이 아니었다. 앞으로 트레바리에서 일어날 모든 비즈니스는 이벤트 기반으로 이루어져 갈 계획이기 때문에, 그 기반을 다질 중요한 작업이었다고 생각한다. 구조적 가치는 미래 지향적이다. '앞으로'의 비즈니스를 위해 잘 구조되어야한다. 당장 뒤에있는 놀러가기 사용 처리, 코호트 분석 작업만 생각해도 그랬다. 다음 프로젝트, 그 다음 프로젝트를 아키텍쳐가 쉽게 적용하고 받아들일 수 있게 뚝딱질을 해야했다. 피처와 기반을 동시에 컨트롤해야하는 상황이었다. 테크 유닛 모두가 그랬다. 하지만 시간은 늘 부족하고, 비즈니스 속도는 중요했다.
보이는 가치와 보이지 않지만 분명한 가치, 이 둘 사이에서 중요한 건 '내 눈'에 보이는 것이다. 어찌됐든 사용자에게 동작하는 소프트 웨어를 보여주어야하니까. 근데 나는 개발자라서 둘 다 보인다. 😂
뉴 어드민 첫 배포에서는 우선 소프트웨어가 동작하고 있으니까 코드의 가독성, 재사용성은 다음 배포에 적용하기로 했고 실제로 그렇게 했다. 매 배포마다 기존의 코드와 피처의 기준을 높여보자는 마음이었다. 그래서 첫 배포 당시 코드를 보면 중복도 많고, 알아보기 힘들다. 그 다음 배포목표는 유저의 티켓을 보여주는 기능이었다. 나는 여기서 중복되는 코드를 없앴고, 테스트 코드를 추가했고, 예외를 핸들링하는 코드를 적용했다. 자잘자잘한 변수명과 메소드 이름도 더 명확하게 재작명했다. '작게 자주 배포하라'는 말이 여기서 이해가 간다. 작은 단위로 자주 전달하면 사용자가 원하는 것을 n분의 1 이라도 보여주되, 소프트웨어의 지속적 개선을 적용할 수 있었다. 근데 이건 개발자의 책임에 달려있는 문제다. 내가 마음 먹지 않는다면 결과는 달라진다.
매 배포 때마다, 기존 피처의 기준을 높일 수 있을까. 매 프로젝트마다 시간에 쫓겨 피처를 겨우 완성하느라 급급한데 기존 코드를 손 볼 시간이 있을까. 사실 뉴 어드민에 코드를 손보는 일도 일과 시간만으로는 턱도 없었다. 개인 시간을 들여야 가능했다. 숙련도를 감안하면 달라질까. 새로운 피처를 적용하느라 기존 코드를 손 볼 시간이 대부분은 없다. 뒤돌아보면 그 땐 그게 최선의 코드였다는 한 개발자의 말이 나는 핑계처럼 들리지 않는다. 어떻게 해야 개발자의 책임을, 늘 다 할 수 있을까. 사용자를 위한 행위적 가치와 미래에 영향을 가할 구조적 가치를 다 잡을 수 있을까.
8. [ ~ 22년 08월 ] 트레바리 청소부 활동 : 써먹을 수 있는 공부를 해보자
쓰고 버리는 공부가 아니라 써먹을 수 있는 공부를 위해 주니어 세 명이 시작한 활동이다. 기술적 부채, 코드 클렌징, 누군가 해줬으면 좋겠는 무언가를 주제로 잡고 진행했다.
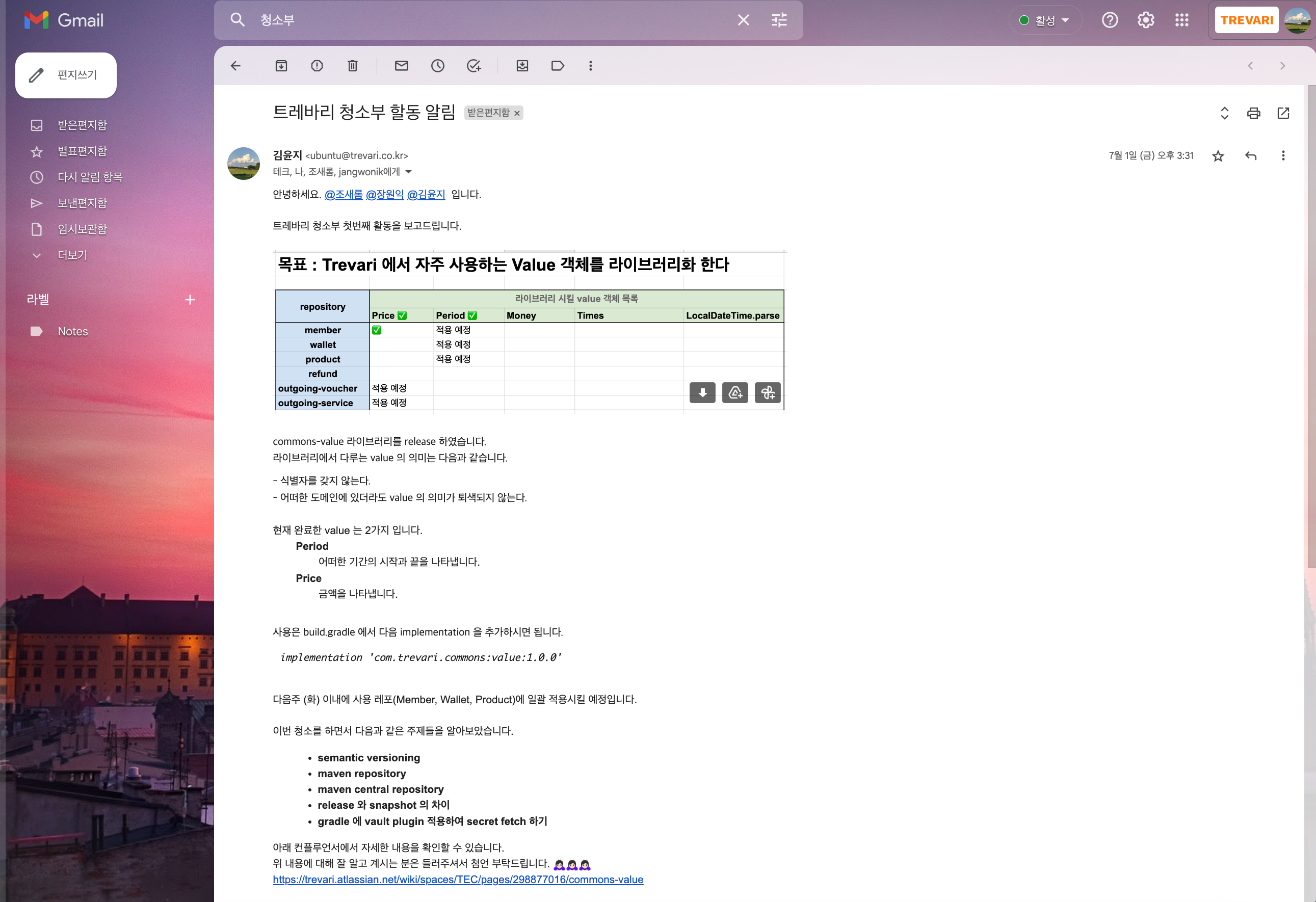
첫 번째 활동은 도메인에서 쓰일 Value 객체들을 s3 repository 에 라이브러리화 하는 작업이었다.
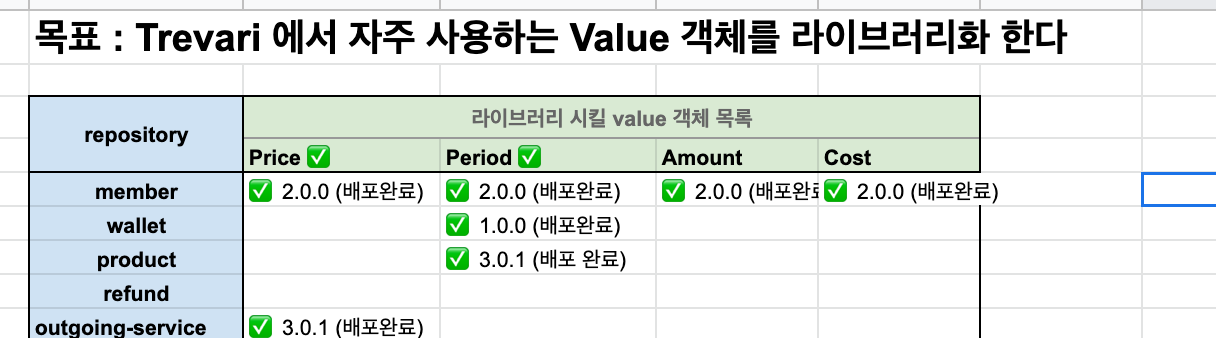
위 프로젝트를 진행하면서 익혔던 것들은 다음과 같다.
- maven repository
- release 와 snapshot 의 차이 🎃 다시 복습할 겸 짚고 넘어가기
- RELEASE 형식의 Artifact를 사용한다는 것은 <version> 태그안에 “1.2.3″과 같이 숫자로만 입력하면 된다.
이럴 경우에, 우선 빌드 시에 로컬 저장소부터 검색한다. 즉, 로컬 저장소(보통 {사용자디렉터리}/.m2/repository) 에 필요한 Artifact 가 있으면 원격 저장소에서 다운로드 받지 않고 로컬에 있는 것을 사용한다. 로컬에 존재하지 않으면 그때 원격으로부터 다운로드 받는다. - SNAPSHOT 설정은 <version> 태크안에 “1.2.3-SNAPSHOT”이라고 정의한다. 이러면 로컬 저장소에 있는 것을 사용하는 것이 아니라 원격 저장소에 있는것을 사용한다. 즉, 로컬에 이미 존재하더라도 원격에 최신의 Artiface가 있으면 그것을 다운로드 받아 사용한다. 그래서 SNAPSHOT을 사용할 때는 Artifact 파일 뒤에 시간과 빌드번호가 붙게된다. 아무리 똑같은 Artifact라고 해도 뒤에 붙은 번호가 다르다.
- RELEASE는 말 그대로 최종 배포될 때 사용되는 것으로 Artifact의 수정이 거의 없을 때 사용한다. SNAPSHOT은 Artifact를 개발중에 다른곳에서도 자주 사용할 때 사용하는 것으로 Artifact의 수정이 빈번할 경우 사용한다.
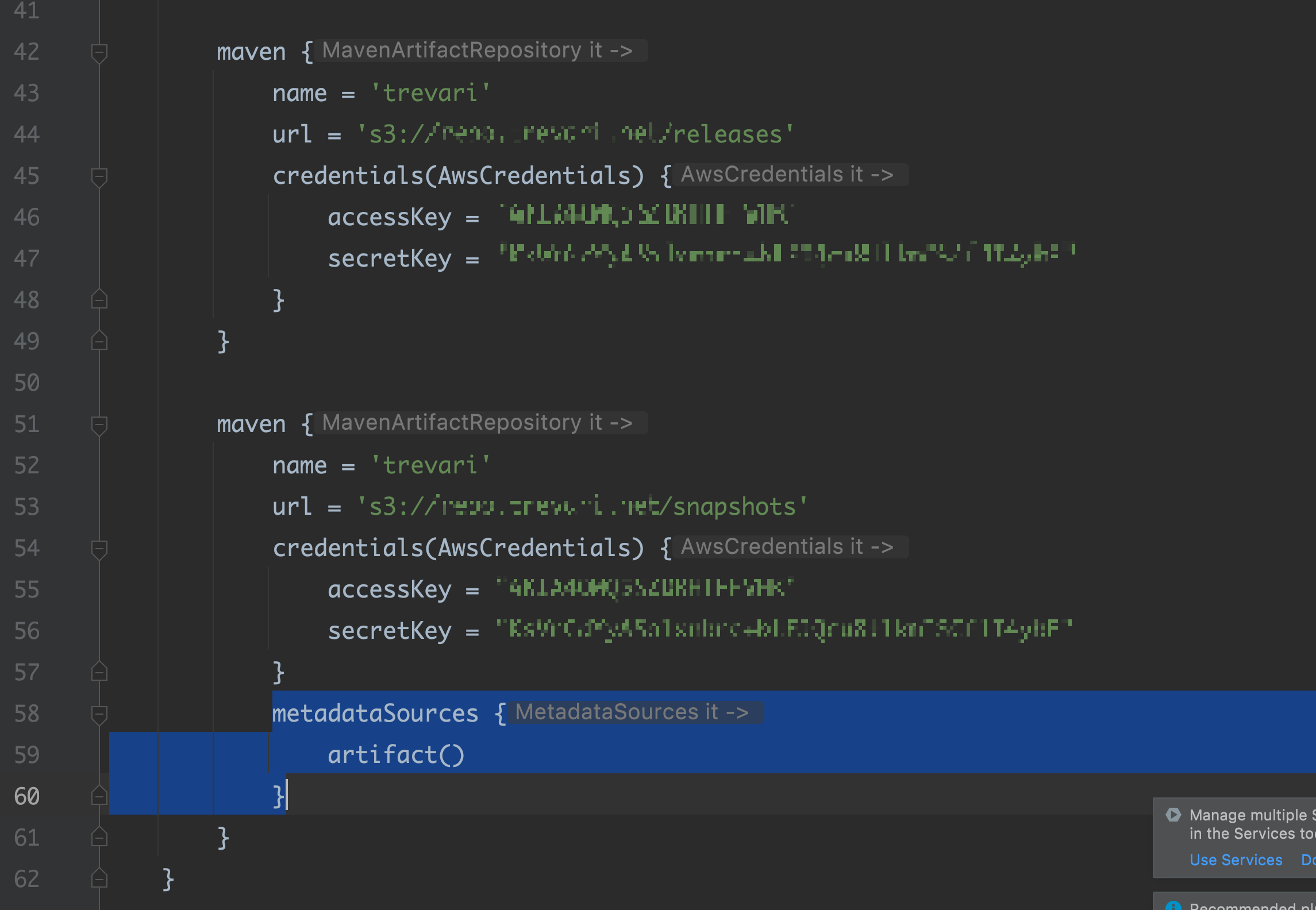
- release 나 snapshot 사용 방법에는 어떤 차이가 있을까? snapshot에는 위 사진처럼 metadataSources 를 명시해주어야한다.
- RELEASE 형식의 Artifact를 사용한다는 것은 <version> 태그안에 “1.2.3″과 같이 숫자로만 입력하면 된다.

- 시멘틱 버저닝
- 버전 번호는 Major, Minor, Patch 의 형태로 배포하고, Major, Minor, Patch 는 각각 자연수이고 절대 앞에 0이 붙어서는 안된다. 각 번호의 수는 항상 증가해야 한다. 특정 버전으로 패키지를 배포하고 나면, 그 버전의 내용은 절대 변경하지 말아야한다.
이 외에 진행하면서 깃헙 태깅 , s3 도 새로 익히게 되었지만, 아쉬운 점도 있다. 우리가 value 객체에 어떤 변경이 일어났을 때, 주 버전을 너무 쉽게 올렸다. versionnig 에 대한 공부를 한 뒤였는데도, 깊게 고려하지 못했다. 왜 그랬을까? 계속 마지막 변경일 것이라고 우리끼리 추측했기 때문이기도 하고, 기존 버전과 호환되냐 그렇지 않느냐 를 기준으로 버저닝을 생각하지 않았기 때문인 것 같다.
트레바리 청소부 활동은 개인적으로 의미가 있었지만, 테크유닛에게는 어떤 의미가 있었을지 잘 모르겠다. 우리가 만든 value 객체를 사용하는 곳은 적디 적다. money 객체를 만들어두었는데, 이 사실에 대해 알지 못하는 사람이 더 많다. 그러니까.. 열심히 만들었는데 사람들이 써먹질 않는거다. 실패다. 😅 사람들의 주의를 이끌 수 있게 공표하는 시간을 더 자주 가졌어야 할 것 같다. 남을 설득하는 건 너무 어렵다. 사실 사람들은 남의 말에 생각보다 관심이 없고, 한번 듣고 잘 잃어버린다. (나 포함..) 그래서 자주 말해야한다. 우리는 그러지 못했다. 그렇게 트레바리 청소부 활동은 시시하게 끝이 나버렸다.
9. [ ~ 22년 09월 ] 내가 정말 완전연소되나 싶었던,, 결제 환불 원장
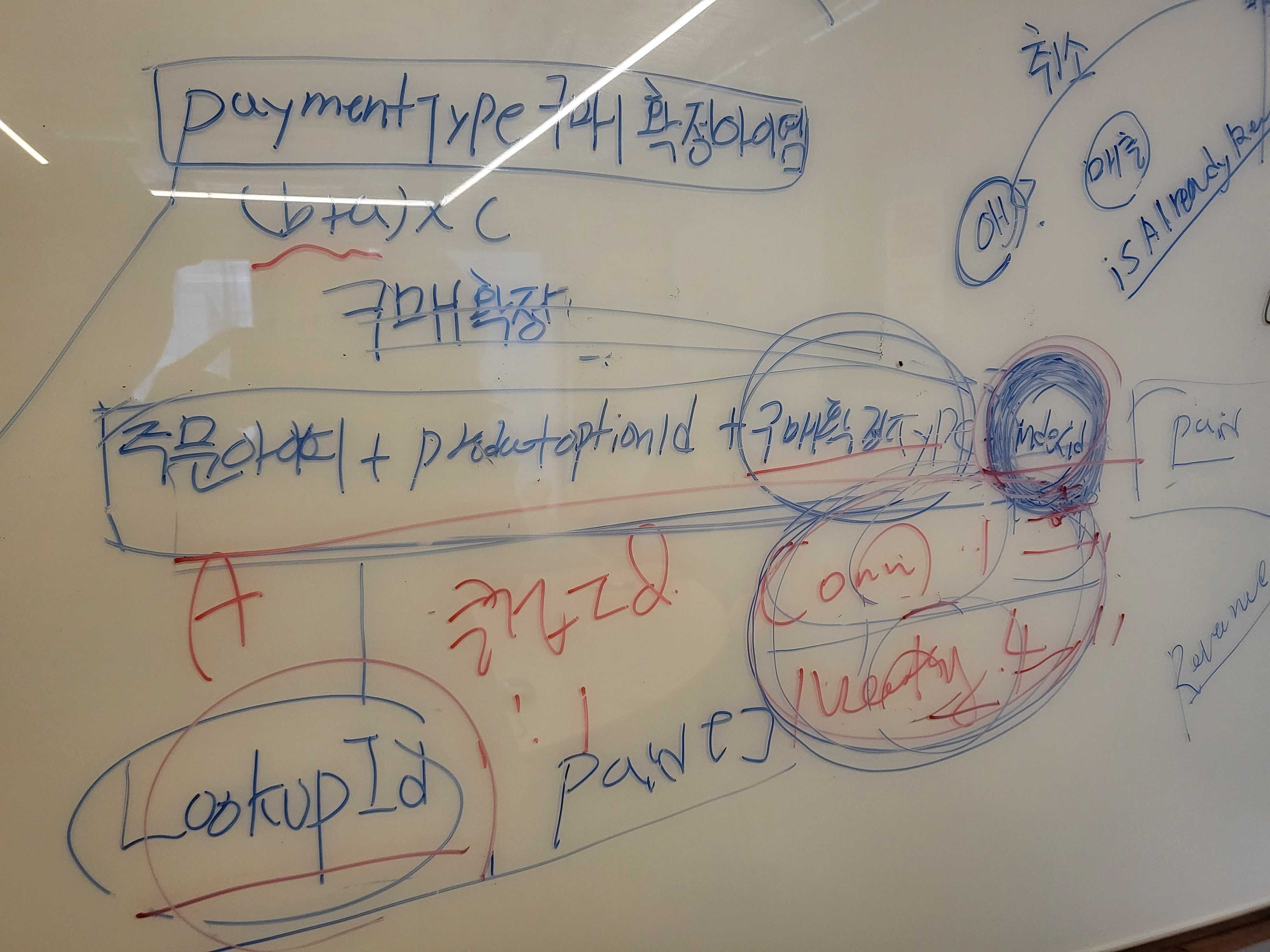
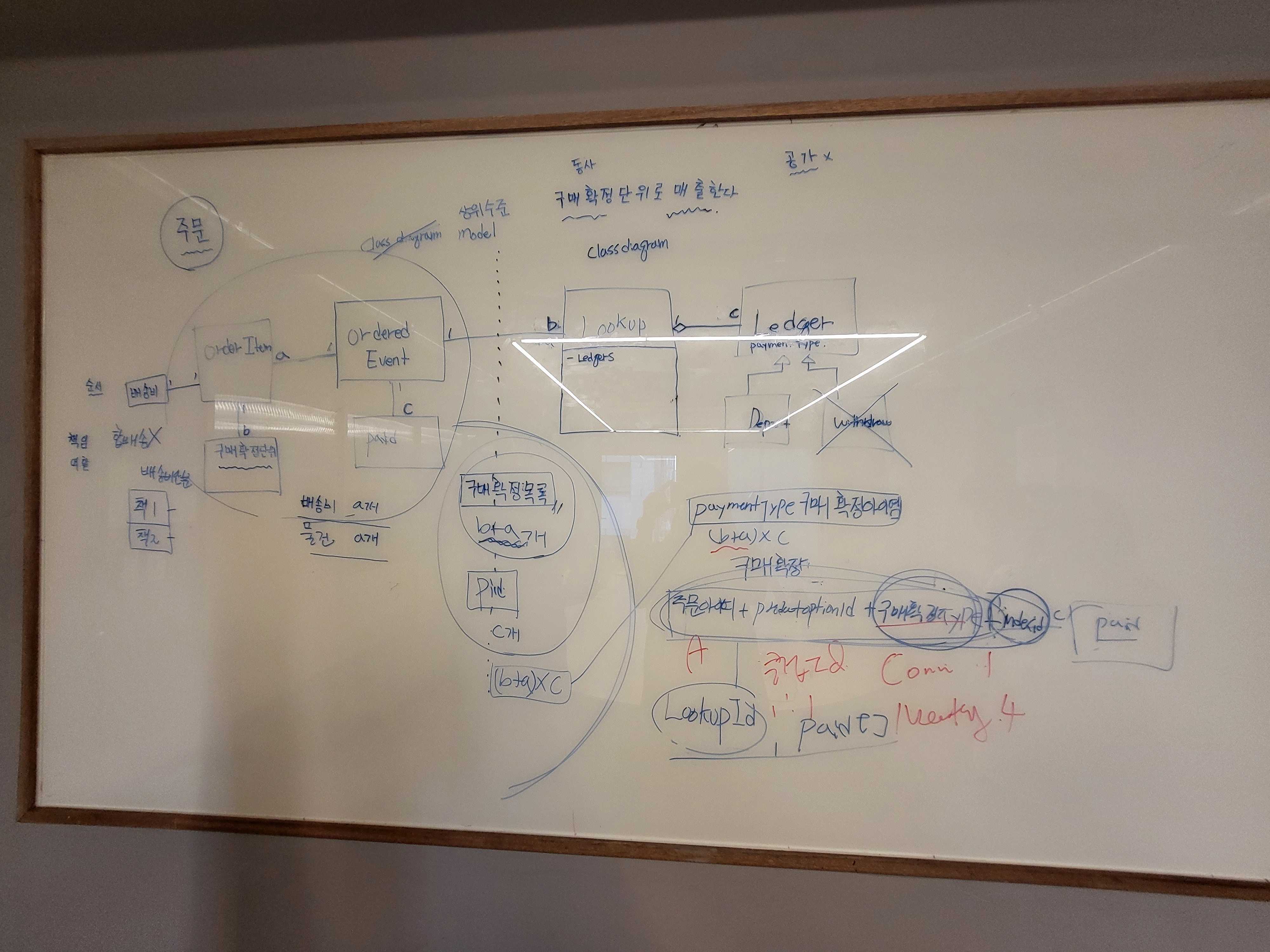
여러 엣지 케이스가 많았다. 각 엣지 케이스는 다른 엣지 케이스의 선행이냐 후행이냐에 따라서도 결과가 달라졌다. 매출 인식 후에 또다시 추가결제(클럽 변경)가 발생하면 그걸 어떤 월 매출로 잡아야하는지.. 같은 식의 문제가 반복되었고, 그 때 마다 실무자와의 미팅이 계속 발생했다.
설계 기간 중, 얼마나 많은 개념이 뒤바뀌었는지 모르겠다. Paid와 Refund 가 생겼다가 없어졌다가 Order와 Cancel 안에 그 개념이 들어갔다 빠졌다가 했다. 매월 5일에 구매확정 시키기로 한 개념도 현재는 유효하지 않다. 근데 정말 그때는 맞았다. 그때는 그게 맞았지만, 함께 얘기하고 구현하다보니 틀리게 되었다. 틀리게 되었다는 것을 드러내기 위해 우리가 그 많은 시간을 보낸건가 싶다. LookUp은 언제까지 LookUp 일 수 있을까. 매출인식키는 indexId에서 PurchasedConfirmKey → LookUpKey → RevenueRecognizedLookUpKey → RevenueLookUpKey로 변했다. 매출 인식에 이어 매출 마감이 구현 마무리 단계에서 갑자기 등장하기도 했다. 고정된 것은 아무것도 없는 것 같다. 소프트웨어 개발이 이런 건가. 발견한다는 완수님이 말이 이런건가. 그렇게 따지면 우리는 꽤 많은 발견을 했지않나.
숙련도가 낮다보니 테스트 해야할 범위를 잡기 어려웠다. 말로만 듣던 zero, one to many 법칙을 적용하고서도 테스트 직경을 구하기가 쉽지않았다. 어디서부터 어디까지 테스트 해야할까. sut가 하는 역할을 단 하나로 산정한다고쳐도 난감한 상황이있었다. @mock 을 사용하지않고 mocking을 해야하는 상황에서도 곤혹스러웠다. 적절할 때에 완수님이 FakeRevenueRecognitionLookUpFinderBuilder 빌더 패턴으로 구현해주신걸 보았다. 그니까 sut 앞뒤의 given, then 을 작성 할 수 있으려면, 그렇게 테스트 할 수 있는 상황이 갖춰줘야했다. 의존성 주입을 받던지, 아니면 fake로 mock을 작성하던지.
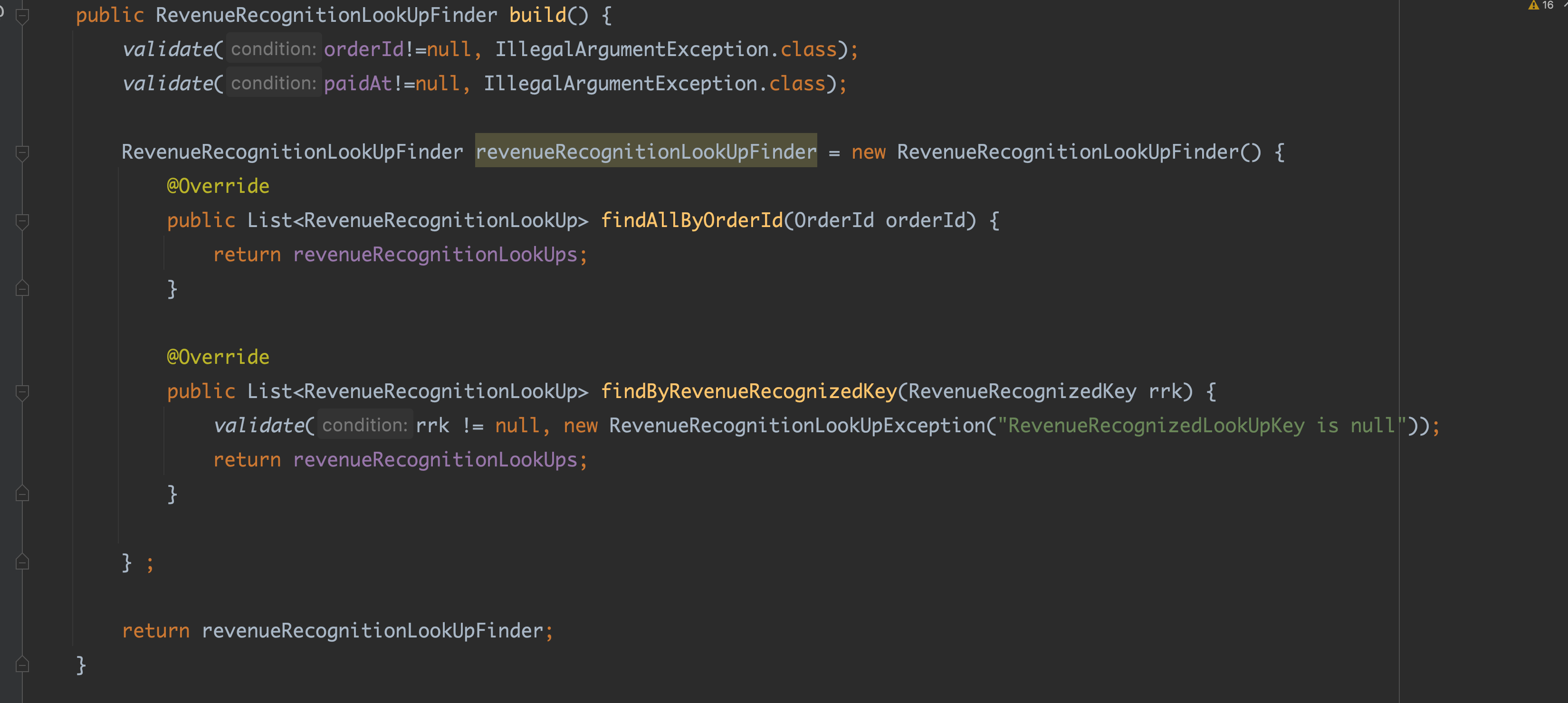
오토 인젝션을 사용할 수 없는 도메인 모듈에서의 테스트 코드는 장황했다. 필요한 모든 given 을 직접 만들어야 했기에 길어질 수 밖에 없었는데, builder 패턴, 도우미 메소드, 헬퍼 클래스가 테스트 가독성에 많은 도움을 주었다. 단언문자체를 클래스로 만들어 단언 코드의 가독성을 높이기도 했다.
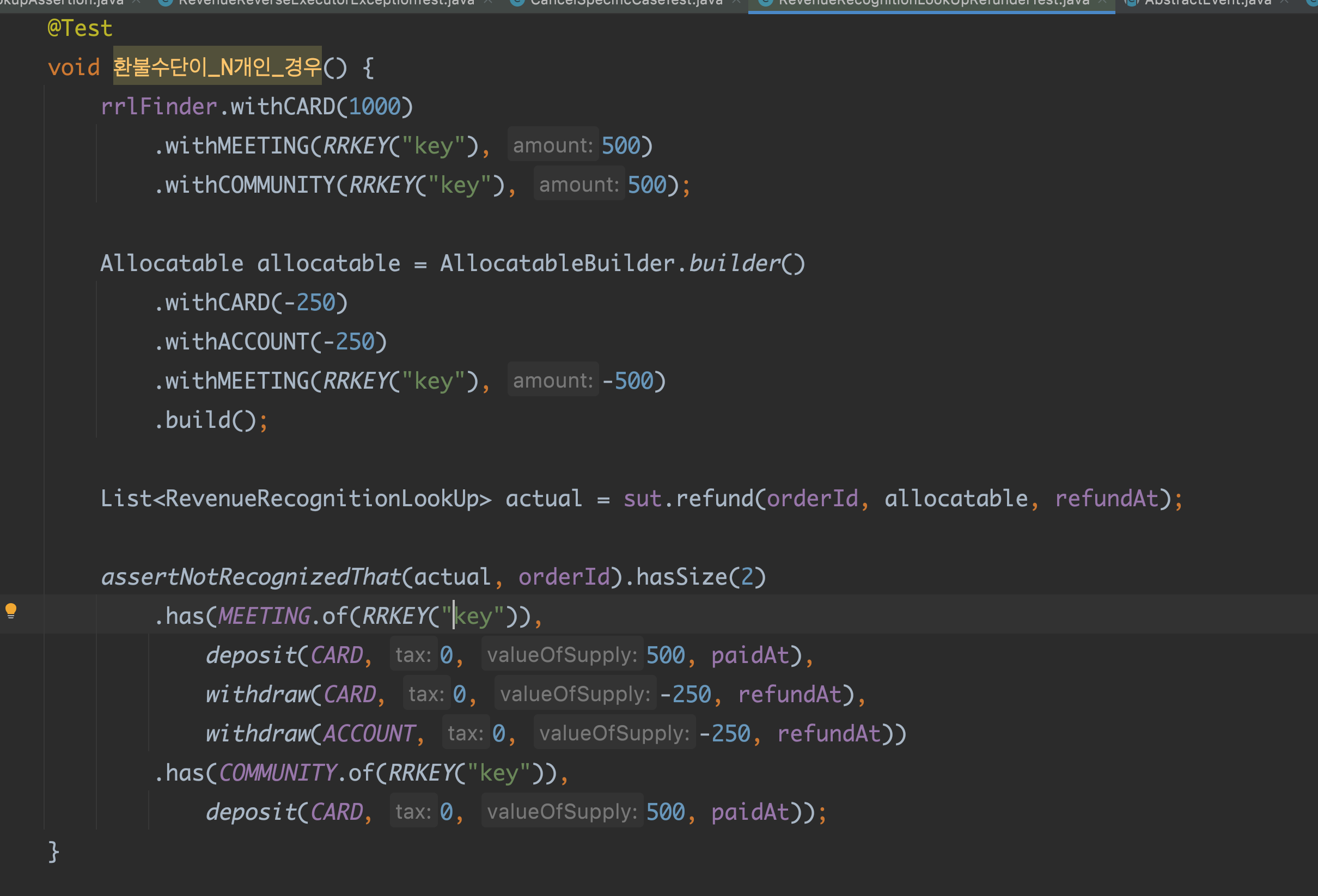
가장 난관이었던 점은 의외로 spring jdbc 구현이었다. spring jdbc 구현은 처음이라 @Version 에 대해 잘 몰랐다. 여기에 시간은 엄청 쏟았다.
- spring jdbc 를 구현하려면 @Version 을 통해 Long version 을 해당 엔티티 객체에 넣어주어야했고, 실제 객체와 다른 엔티티를 따로 만든다면 update 개념의 save() 이용시 에러가 난다는 것이다. 따라서 그 때는 원래 해당 엔티티를 찾아와서 해당 version +1 로 다시 update 해줘야한다. 근데 이 때도 스프링 jdbc 가 기본적으로 제공하는 메소드와 커스텀으로 인터페이스에 명시한 메소드가 충돌하는 경우가 있었다. ex) void update().
문제가 하나 더 있었다.
- 저장하는 엔티티 구조와 객체의 필드가 일치 하지 않는 경우였다. 매출인식을 위한 키는 A와 B로 이루어져있는데 저장하는 엔티티에서는 이 둘을 별개의 컬럼으로 쪼개 넣어야했다.
- 이런 저런 이유로 시도를 계속 해보다가 결국 jdbc template 을 이용했다.
이 외에도 나는 해당 프로젝트를 하면서 배웠던게 많고도 많다.
📍 헬퍼 클래스 / 도우미 메소드
test에서 helper 클래스를 만들어서 mokito.mocking 이 어려운 객체들을 대신 mocking 했다. 또는 복잡한 로직으로 인해 가독성이 힘든 테스트 클래스에서 도우미 메소드를 활용했다.
📍 handler 와 dispather
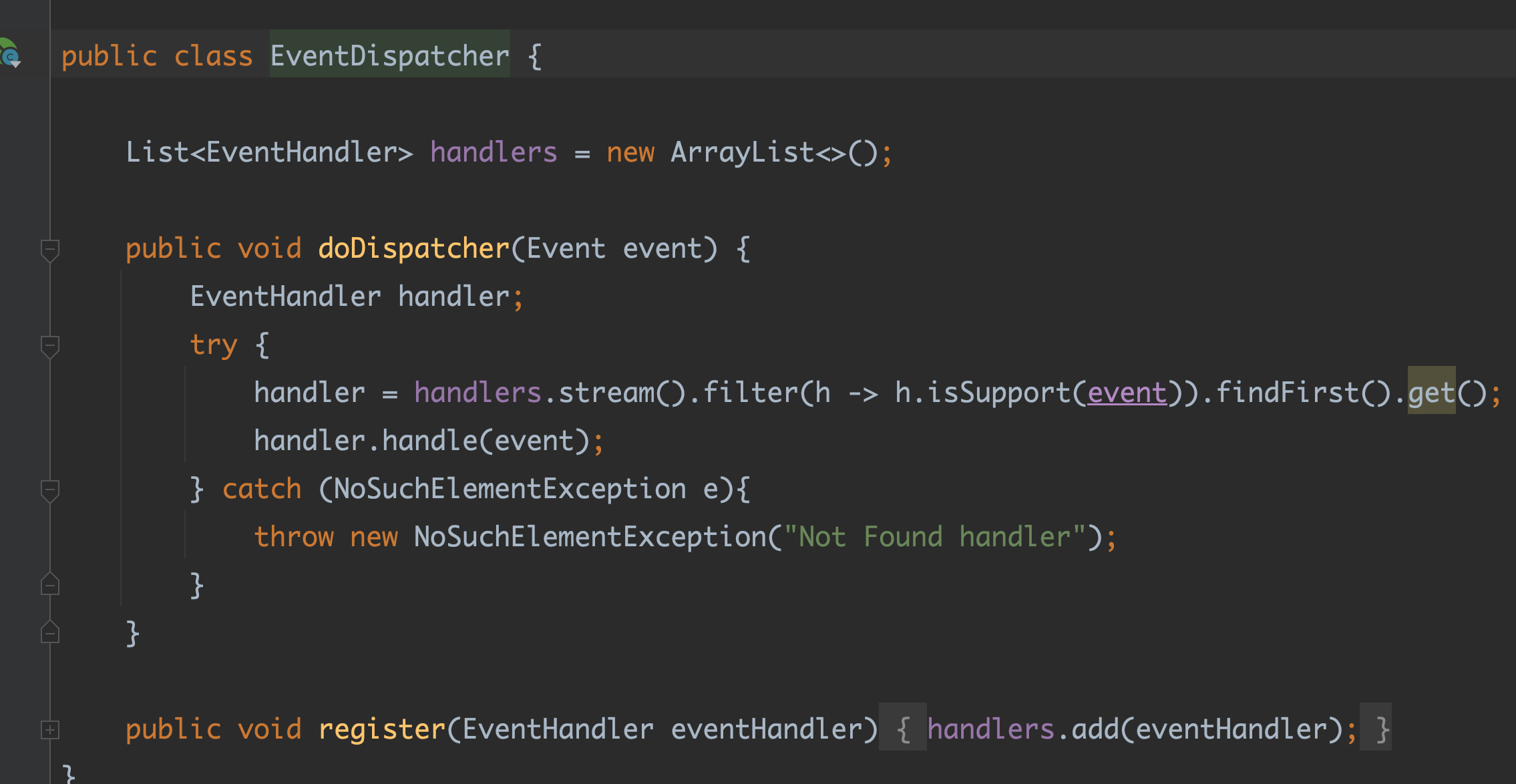
dispatcher 는 핸들러를 가지고있고 클라이언트가 event 를 dispatcher 하고자하면 가지고 있는 핸들러들을 하나씩 돌면서 "너 이 이벤트 지원하니" 라고 물어본다.
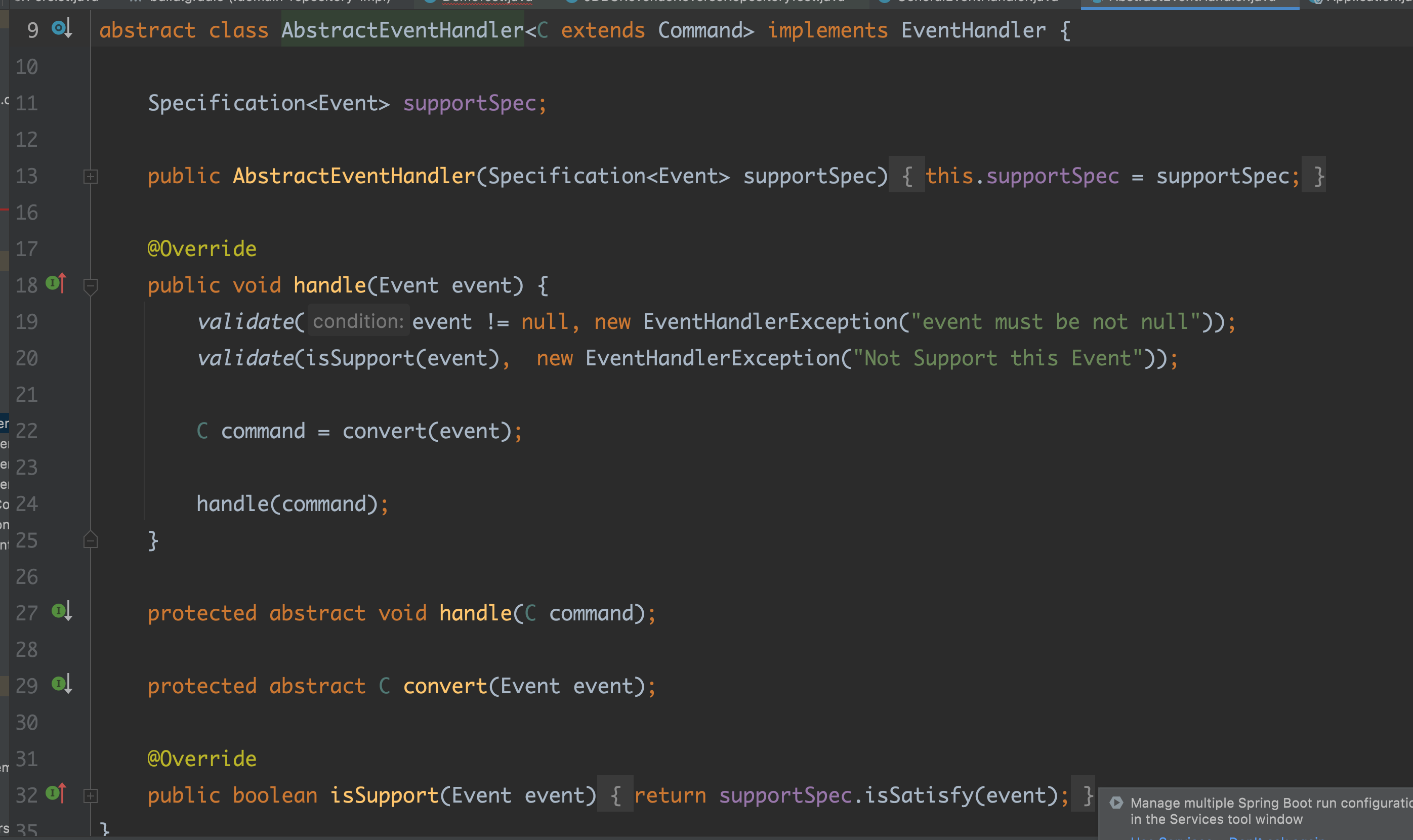
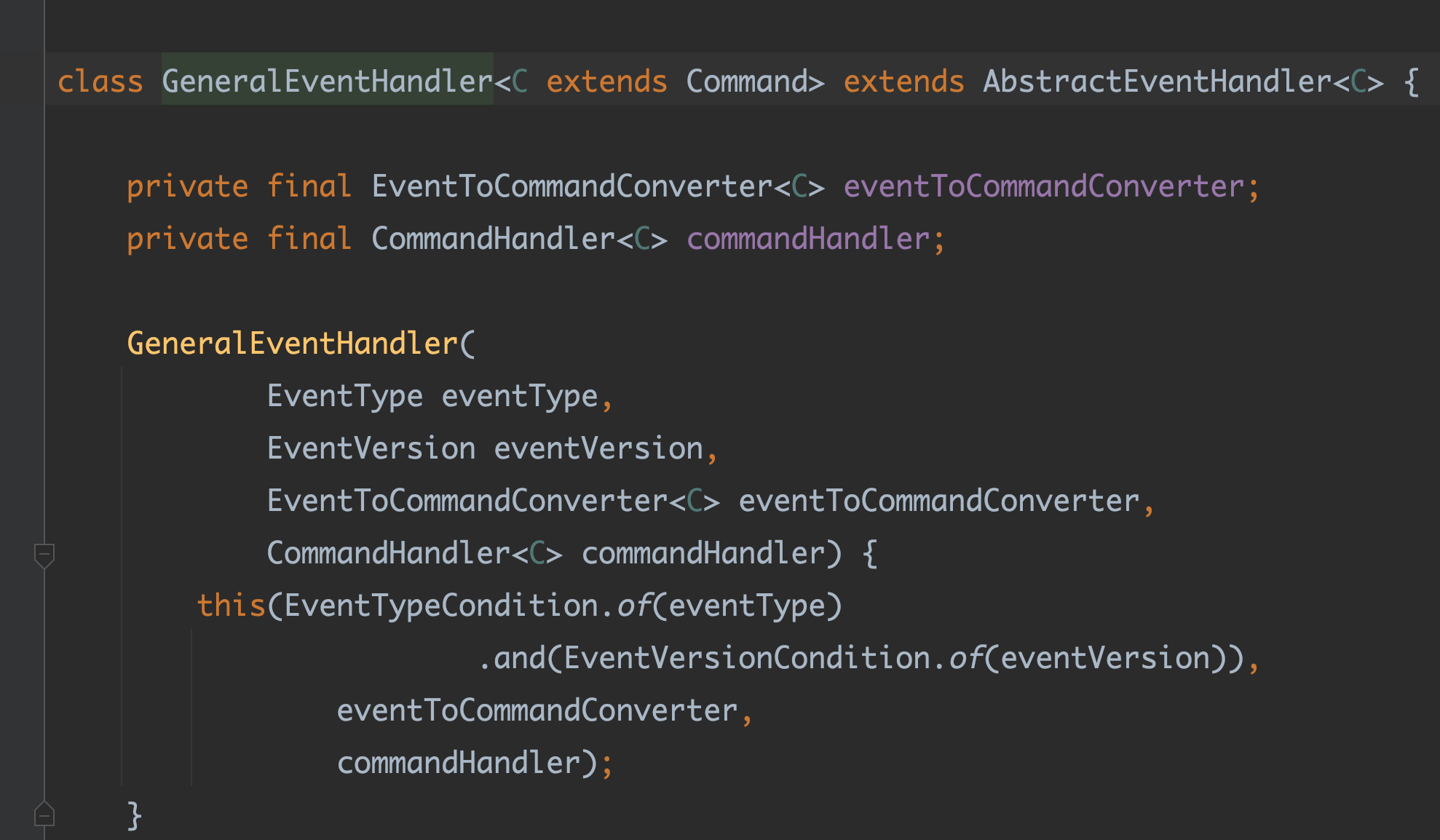
핸들러는 자신이 처리할 이벤트의 정보와 더 가까워지게 된다.
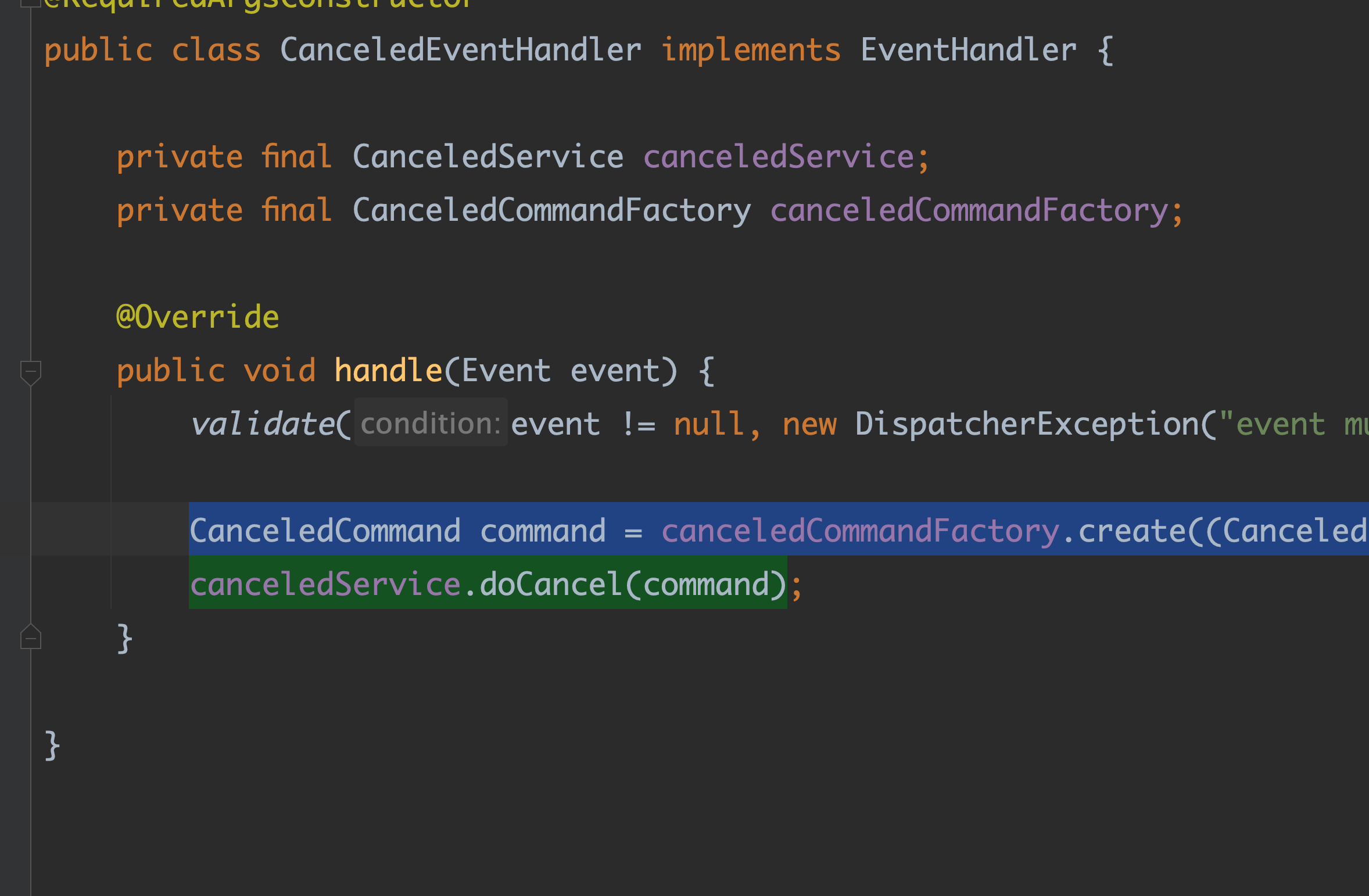
Commandconverter 는 event에 의존한다. 이벤트는 버전 별로 커맨드를 만드는 로직이 다르다. Commandconverter 와 handler 는 쌍인거당...
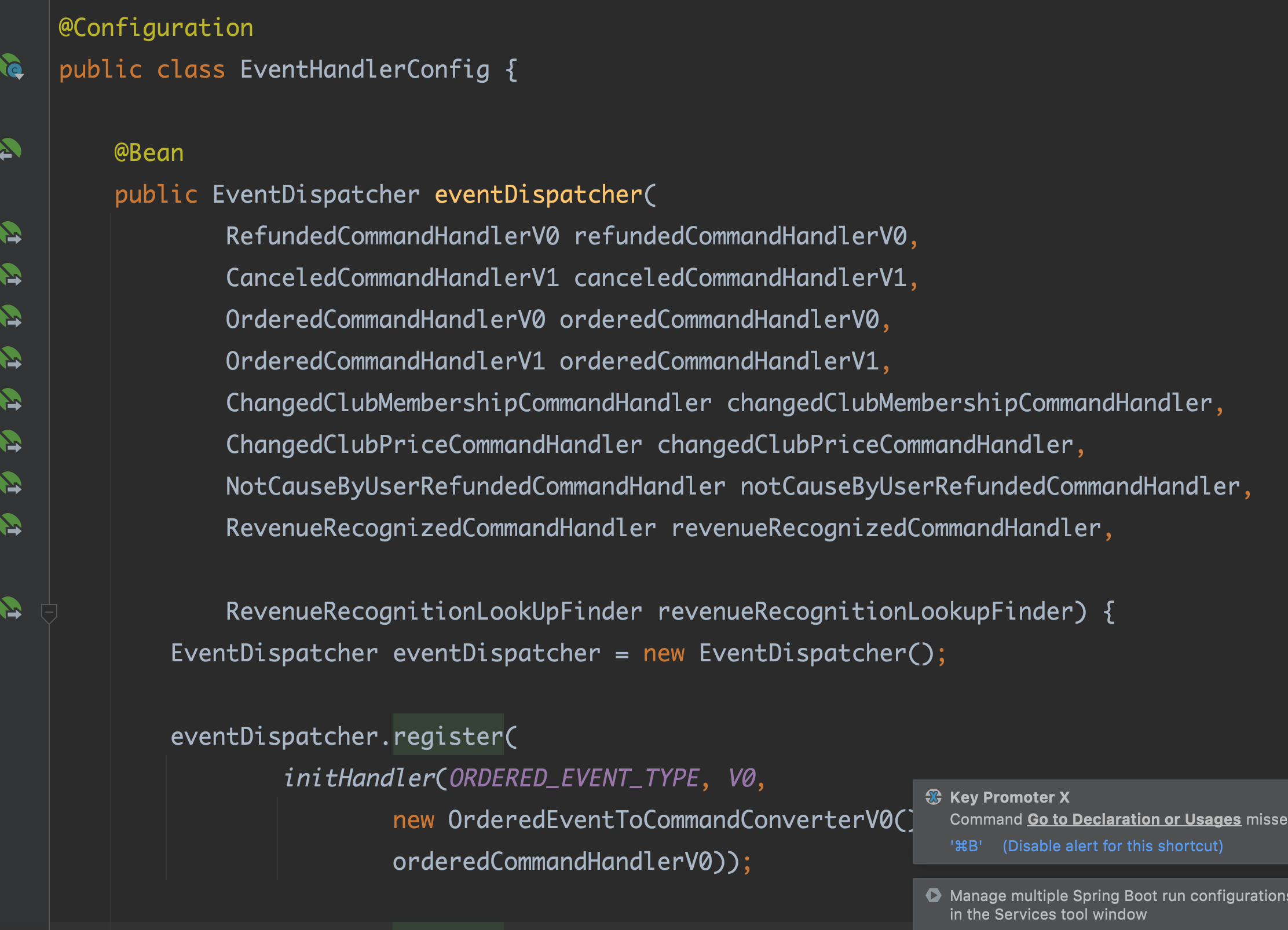
모든 핸들러 구현체는 이벤트를 검증 후, 커맨드로 변경 하고 애플리케이션을 호출한다. 이런 발견을 구현 내내 하면서 initHandler 메소드의 시그니처 형태가 자리잡게 되었다.
initHandler(이벤트 타입, 이벤트 버전, 이벤트 커맨드 컨버터_버전, 커맨드 핸들러_버전)
📍 JDBC TEST
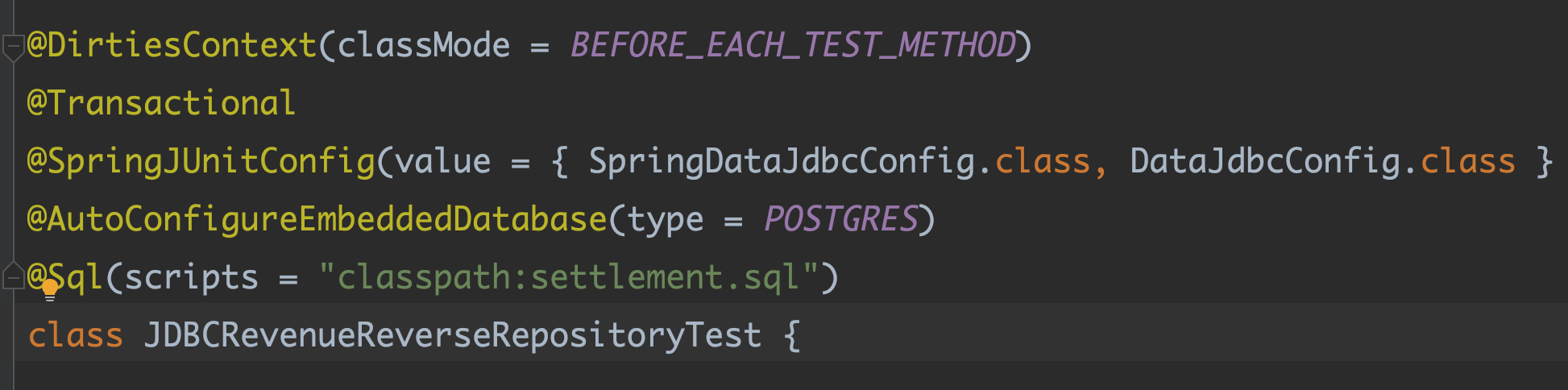
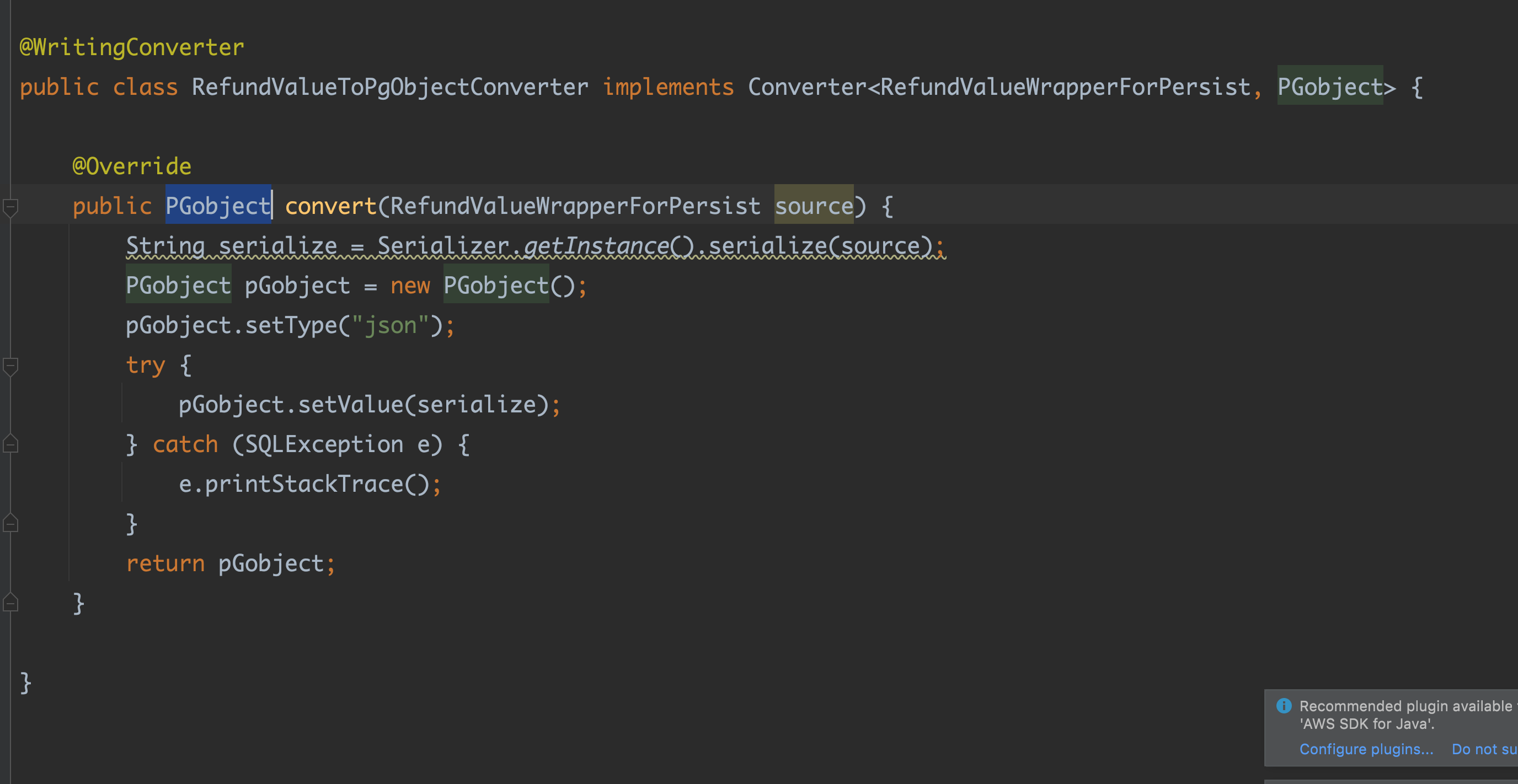
docker 를 이용해 container repository 테스트를 진행했다. 해당 과정에서 Json 컬럼을 직렬화, 역직렬화하는 @WritingConverter @ReadingConverter 도 익혔다.
📍AdapterPattern
- 이벤트 페이로드와 도메인 간의 느슨한 결합을 위해 어뎁터 패턴을 이용했다. 어뎁터는 결제 또는 환불한 금액을 상품 유형과 가격 비율에 따라 안분하고 도메인 로직에 어뎁팅 될 수 있게 변환하는 역할을 했다.
📍Packaging
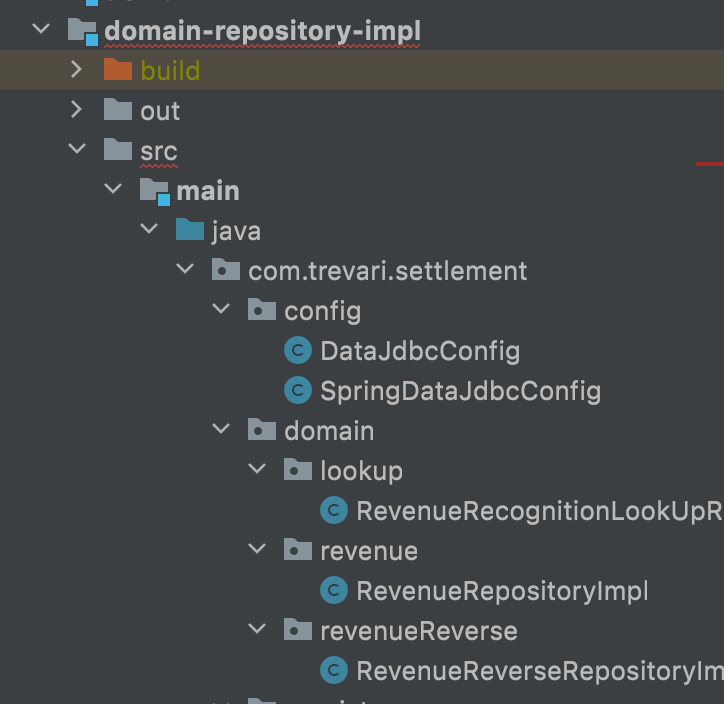
* domain.lookUp * domain.revenue * domain.revenueReverse 는 domain 모듈과 함께 맞춰 패키징 된 것이다.
📍 그 외,
- 변수명, 클래스 명 : 중요한 키워드가 앞으로 오게 한다.
- AllocatableCanceled 보다는 CanceledAllocatable
- SRP : 하나의 케이스는 하나의 일만 한다.
- 환불과 매출 인식 뒤 환불을 분리한다.
- DIP : interface 와 구현을 분리한다. 도메인을 구현은 interface 를 통해 진행한다. 최종 interface 구현은 나중에 하게 되었다. 저수준 모듈이 고수준 모듈에 의존해야한다.
- LookUpRepositoryImpl *implements* LookUpRepository
- 테스트의 직경 구하기 : 해당 클래스 대상이 하는 역할과 책임을 확실히 정하면 테스트 하기가 쉽다.
- 느슨하고, 독립적이게.
- message-consumer 는 약간의 도메인 로직만 분리하면 아무데서나 다 가져다 쓸 수 있게된다.
- 독립적 모듈(appilication, allocation(안분)) 로직의 지속적 변경에도 끄떡없는 domain 모듈을 구현한다
- allocation 역시 독립적으로 사용할 수 있도록 최대한 루즈하게 만들었음(Object를 받아서 안분이 필요한 어떤 객체든 넣어줄 수 있음)
- domain to outside
해당 프로젝트의 큰 흐름은 다음과 같다.
message -> event -> dispathcher - command -> handler(집합소) -> executor -> domain
아쉬웠던 점
중간 미팅 전까지, 우선 집중해야할 것과 차후 집중해야할 것을 고려하지 못했다. 선택과 집중을 해야하지 않았을까. 우선 event application 과 message consumer 둘 중에 전자를 먼저 끝내놓았다면 실무자와의 1차 데모 미팅에서 더 많은 것을 보여줄 수 있지 않았을까… 🥹
10. [ ~ 22년 10월 ] 코호트 분석 : 생애 첫 트레바리 경험 유저는 현재 retension이 어떨까
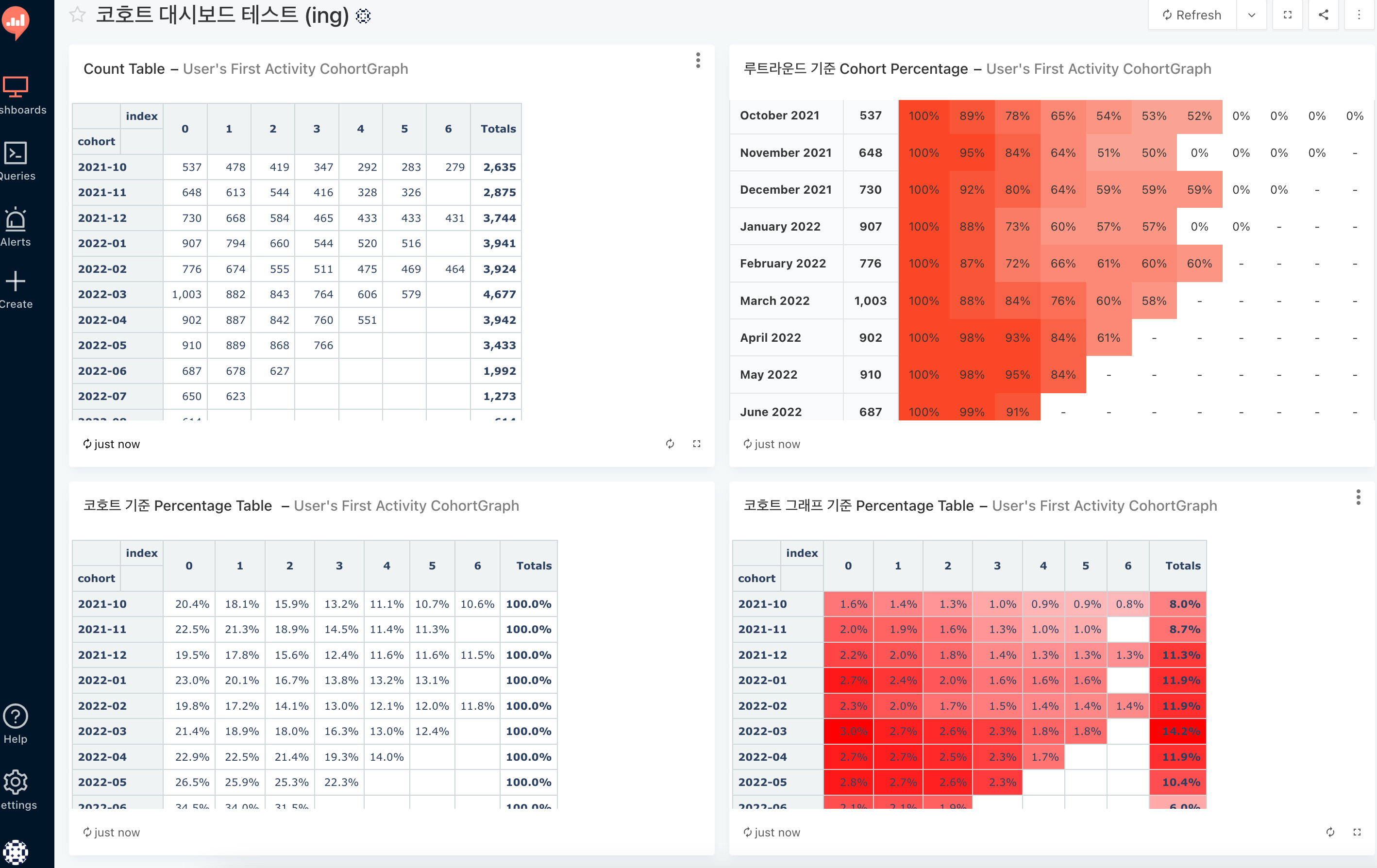
📍생애 첫 트레바리 서비스 경험 유저들은 어디로 갈까?
문제상황
- 트레바리 경험한 유저들의 retension 을 알 수 없음
- 처음 서비스를 이용한 유저의 기준이 없었음
- 관련 데이터인 클럽 신청은 history를 가지고있지 않았음
Behavor
- 해당 이벤트에 대해 정의하고 비동기로 이벤트를 받아 처리함.
- 이벤트 18만건 으로 2015년 ~ 2022 년까지의 코호트가 만들어짐 (라운드는 78개)
Impact
- 평균적으로 4번의 독서모임 이후에 리텬션이 50% 이하로 떨어짐 최종적으로는 7,8% 밖에 안 남는 그림이 됨.
- 씨드를 넣고 변하는 속성과 변하지 않는 속성을 구분하여 해당 코호트에 대해서 필터링 진행예정
- 몇 번째 모임에서 이탈률이 유독 높을까? 해당 모임 퀄리티를 개선하는 것의 우선순위를 높일 수 있을 것이다.
- 예술 클럽으로 트레바리를 시작한 멤버 vs 마케팅 클럽 으로 트레바리를 시작한 멤버, 어떤 케이스의 리텐션이 더 높을까? 리텐션 기여도가 높은 트레바리 클럽 그룹은 무엇일까?
📍기술화를 하면서 특이점

- active 상태인 User 를 어떻게 알 것인가. = 코호트 대상 결정
- active 라는 것은 무엇인가. = 코호드 대상을 결정하는 상태 정의
📍진행하면서 발견한 도메인
- 각 라운드에서 다음 라운드 들은 첫 라운드(루트라운드)의 씨드 개수를 넘어설 수 없다.
- 첫 라운드는 다음 라운드에 계승된다.
- 씨드는 해당 코호트에서 유일하다.
- lazy applier = 씨드가 나중에 적용되는 케이스가 있다. '새로운 도메인 탄생'
- 루트 라운드가 특히 중요하다. 왜냐면 모든 코호트는 루트라운드를 기준으로 추적 하기 때문..!
📍진행하면서 배우고 느꼈던 점
- validate와 violation을 구분해야한다.
- multi module 도 단점이 있다.
- 변하는 것과 변하지 않는 것을 구분해야한다.
'회고 > 여을심은 열심중 2022회고' 카테고리의 다른 글
| 여을심은 그동안 어디서 뭘 했을까 (3) | 2022.11.04 |
|---|
